
はじめに
インテルのCore i系CPUは第12世代(2021年)以降、すべからくPコアとEコアが搭載されるようになっているが、実はCAEの用途を考えると、Eコアはほとんど役に立ってくれないという、意味のない進化であった…ということを、OpenFOAMの標準チュートリアルAllrunの記事にて検証した。
但し、上記の結論は、MPIを使った領域分割型の並列計算について言えたことであって、マルチスレッド型の並列計算についてまで言及したものではない。
一方、DEXCSにおける標準メッシュツールであるcfMeshはマルチスレッド型の並列計算で動くので、ここではcfMesh(cartesianMesh)の並列性能について検証した結果について取りまとめた。
Table of Contents
供試マシン
検証に使用したマシンは以下の2台で、昨年に購入したものである。
- ノートPC
- CPU Core i5-1335U
- メモリー 48GB
- BTOデスクトップPC
- CPU Core i9-14900L
- メモリー 128GB
また、各CPUのPassMarkによるベンチマークを以下に転載しておく。
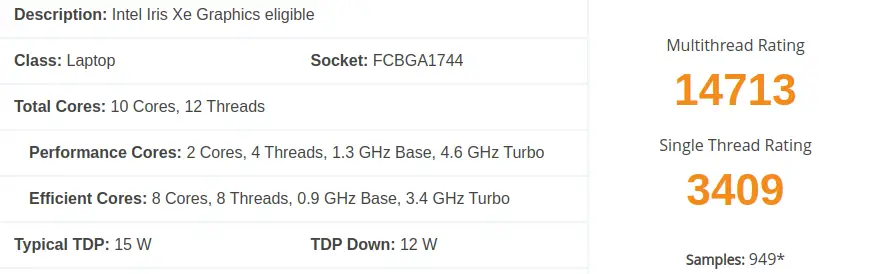
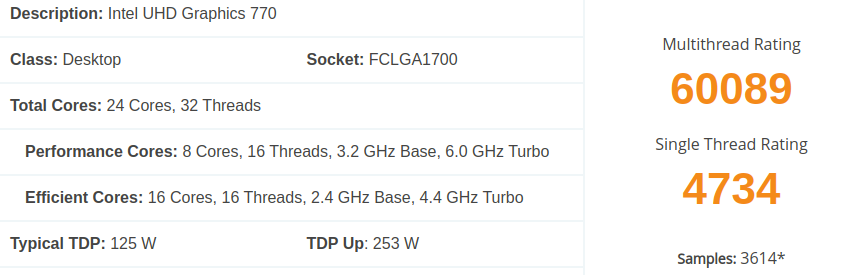
供試モデル
供試モデルとして、以下大きくメッシュサイズの異なるケースを用意した。
- 小規模モデル
- DEXCS標準チュートリアルをデフォルトパラメタで実行、約20万セルのケース
- 大規模モデル
- 実際の熱交換器を対象とした複雑で多くの狭い流路から成る約1000万セル級のケース
検証要領
スレッド数変更方法
cfMesh(cartesianMesh)は、DEXCSランチャーから起動した場合は計算環境で使用可能な全スレッドを使用した計算を実行することになるが、OF-専用端末を開いて、以下のようにして
$ export OMP_NUM_THREADS=4
$ cartesianMesh
環境変数(OMP_NUM_THREADS)の数(上例では4)を指定して実行することでスレッド数を変えて計算ができるので、横軸をスレッド数、縦軸を計算速度(clockTime)としたプロット図にて取りまとめることとした。
計算環境(実マシンか仮想マシンか)
また、計算環境として基本的にはDEXCS2014としているが、これをLinuxの実マシンとして構築したものと、仮想マシンとして構築したものとの違いも調べ、凡例で区別できるようにしておいた。つまり、
- Native(Linux 実マシン)
- VBox(VirtualBox 7.1.4 r165100)
- VM(VMWare Workstation 17 Player 17.6.1)
であり、仮想マシン(VBox,VM)の後ろの数字は、仮想マシンに割り当てたプロセッサ数を表している。
BIOSのハイパースレッド設定
結果
とりあえず、結果のプロット図を示しておく。
小規模モデル on Core i5-1335U

(注)VM12は仮想マシンに対する過剰な(推奨数を超えた)プロセス数指定になるので、さすがに性能は大きく低下している、
小規模モデル on Core i9-14900K

大規模モデル on Core i5-1335U

大規模モデル on Core i9-14900K

考察
特に仮想マシンでの計算では、ベースマシンの負荷状況によって影響を受ける場合があるなどして、データのバラツキもある。以下、あくまでここに掲載したデータだけからの考察である点はお断りしておく。
- 概ねスレッド数が多いほど計算速度が速くなっている
- VirtualBoxにおける高スレッド数計算はバラツキ大で遅くなってしまうものもある
- やはり、実Linuxマシンで計算するのが一番速い
- VMPlayerはわずかに実Linuxマシンに劣るが、遜色ないデータもある
- BIOSのHTをOnとすれば、Offに比べて速度向上が見られた(大規模モデル、実Linuxマシン)が、その差わずか(10%以下)であり、MPI計算での性能低下を斟酌すれば、やはりHTはOffにして使用することが推奨されそう。