本記事は、E.Mogura’s OpenFOAM(全Allrunのデータベース)のページに掲載する予定であったが、当該サーバーの記事投稿システム(Elementor)が不調の為、記事のコピーをこちらに掲載しておく。
先の新サーバーは元々デスクトップマシンとして購入したものを旧サーバーが昇天した為、やむを得ず転用したものであり、計算サーバーとしては無駄なコア(Eコア)が多すぎ、実質8コアのマシンでしかなかった。そこで新々サーバーとして正味16コアを使えるマシンを導入したので、早速やってみた。
基本的に、先の記事(v2406)に記した方法に加えて、v2412で記した多並列計算リストを参考に16並列以上のケースで、余裕をとって14並列の計算になるよう変更し、ほぼログ解析まで問題なく実行でき、残された手作業項目や、実行エラーしたケース等についても全く同一であった。
それにしても、何故v2406なのかという疑問もあるかと思うが、新サーバーには、DEXCS2024の諸々改良版のテストインストールも兼ねてセットアップしたもので、そこからすぐにやりたい!となったので、v2406になった次第である。
Start : 2025-02-19 18:39:51 / Finish : 2025-03-11 03:18:18
- IO/cavity_parProfiling 20
- incompressible/adjointOptimisationFoam/sensitivityMaps/motorBike 20
- incompressible/adjointOptimisationFoam/shapeOptimisation/motorBike 20
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/3DBox/losses 60 -> 12 hierarchical(3 2 2)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/3DBox/losses-mass 60 -> 12 hierarchical(3 2 2)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/3DBox/losses-mass-uniformity 60 -> 12 hierarchical(3 2 2)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/3DBox/losses-mass-uniformity-SQP 60 -> 12 hierarchical(3 2 2)
- incompressible/pimpleFoam/LES/planeChannel 36 -> 14
- incompressible/pimpleFoam/LES/periodicHill 16 -> 12 simple(3 2 2)
- incompressible/pimpleFoam/LES/wallMountedHump 16 -> 14
但し、1〜3のケースについては、先の記事に記したように、変更にミスしている。また最大16コアは使えるはずだが、余裕を見て、14コア(8, 10)12コア(4〜7, 9)としてみた。
データベースのグラフ化による比較
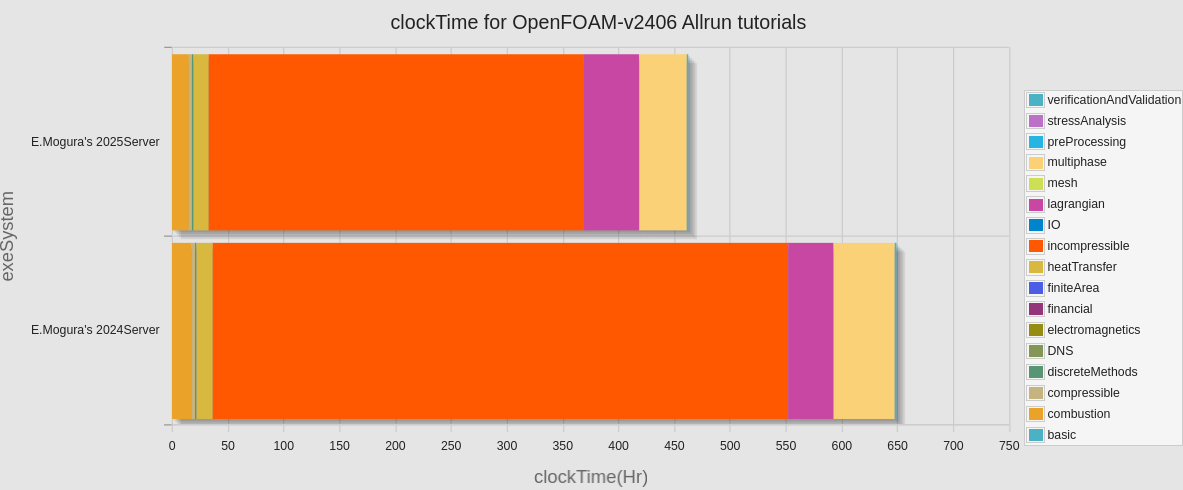
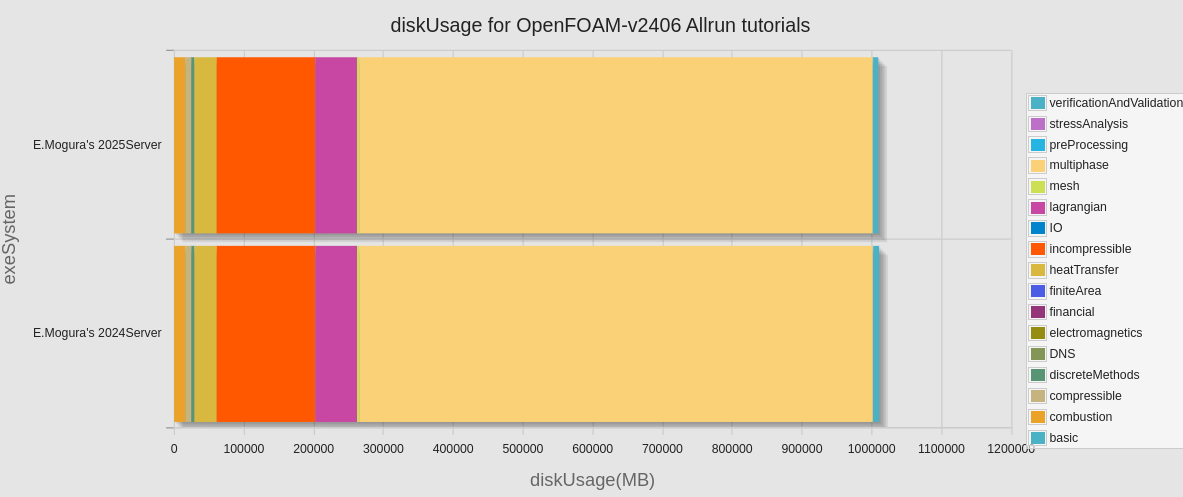
念の為、ディスク使用量の変化についても調べたのと、カテゴリ別、チュートリアルケース毎で計算時間の比較を実施した。
ディスク使用量の違いについても調べたが、ほとんど同じであり、間違いなく同じ計算をしていることは確認できたと言えるだろう。
lagrangianを除いたほとんどのカテゴリで計算時間の短縮が見られた。

incompressible での時間短縮が際立っているのは、多並列での長時間計算がここに集中しているからである。
個別のケースについて、新旧の計算サーバーでの計算時間(sec)を散布図としてプロットした。横軸が旧計算サーバー(Core i9-14900K)、縦軸が新(Ryzen 9 9950X)の計算時間 clockTime (sec)である。
参考に、等速(x 1)のラインも示しておいた。ラインよりも下にあれば高速化しているということである。ラインから大きく外れたケースには矢印ボックスにて番号を付与してあるが、具体的なケース名や数値は、ケースリストにて参照できるようにしておいた。
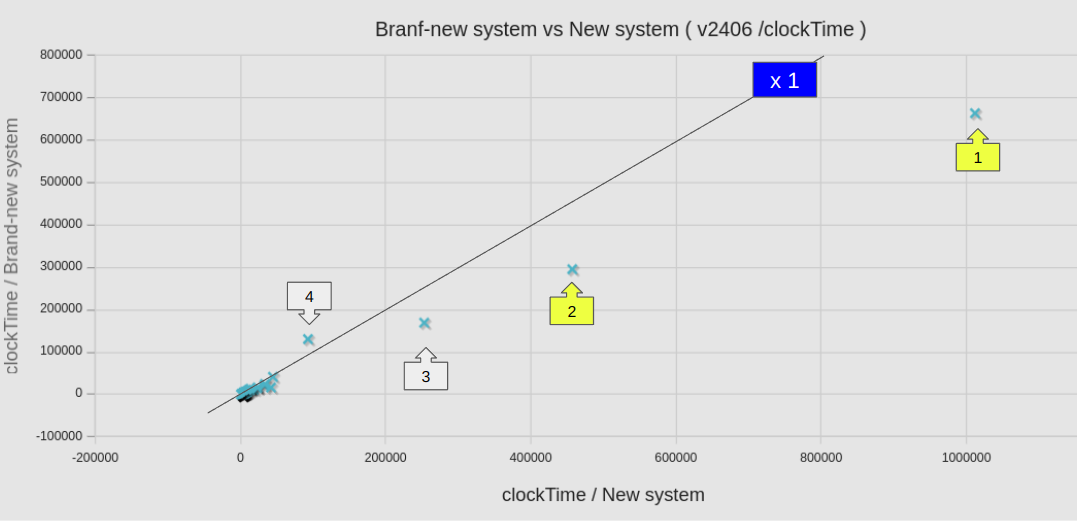
黄色の矢印ボックスで示したのは、8を超える多並列計算ケースであり、すべてのケースにおいて明確な速度向上を見て取れる。
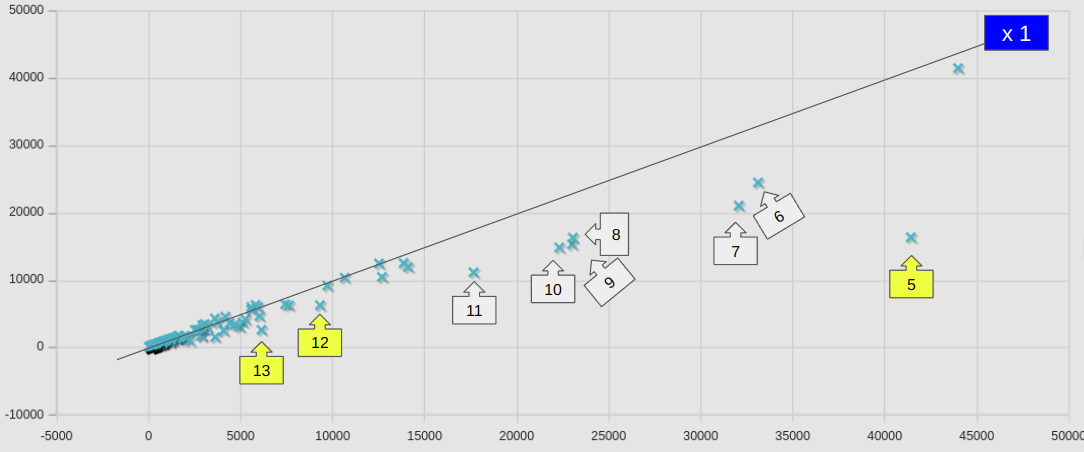
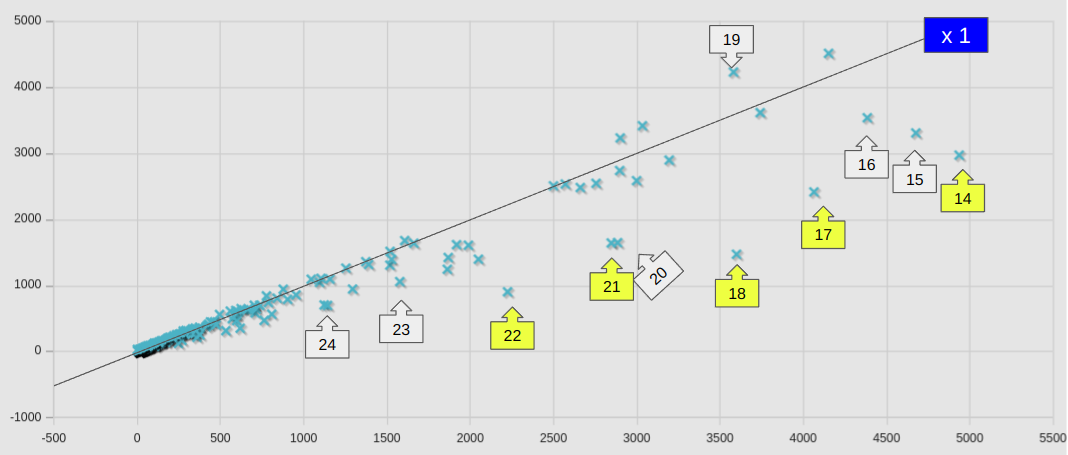
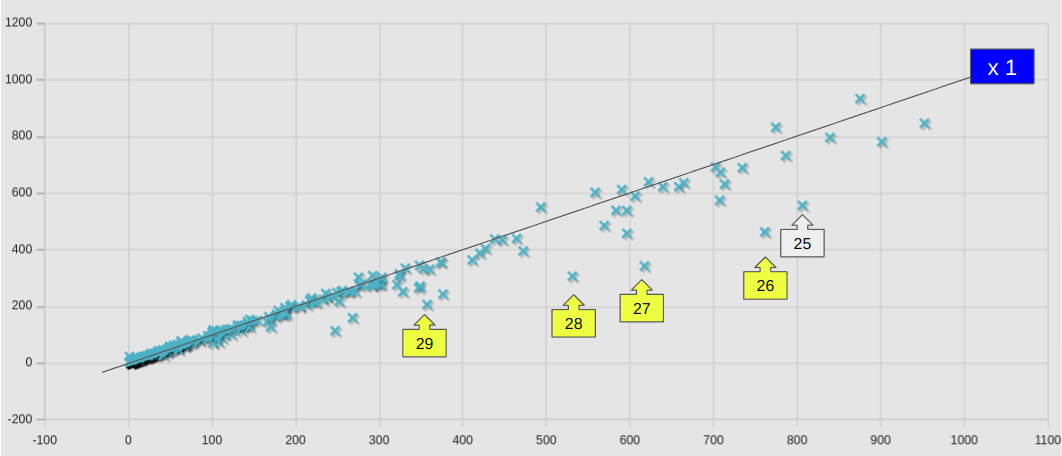
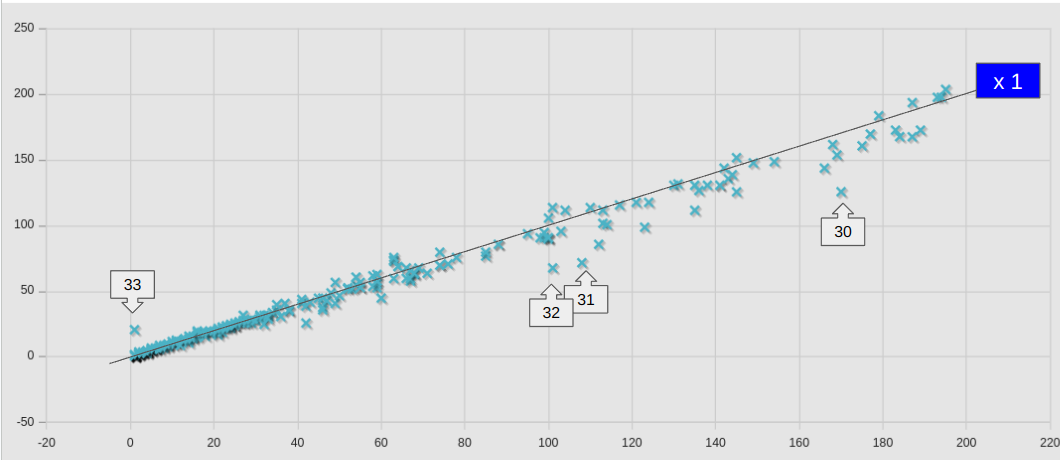
ほとんどのケースで、速度は同等か向上していたが、わずかながら悪化していたケースもあった。No.4, 19 あたりが該当するが、いずれもlagragian のカテゴリーケースであり、lagragian のカテゴリ全体としての悪化の要因であった。
ディスク使用量についても、念の為にとケース毎に散布図にて比較してみた。
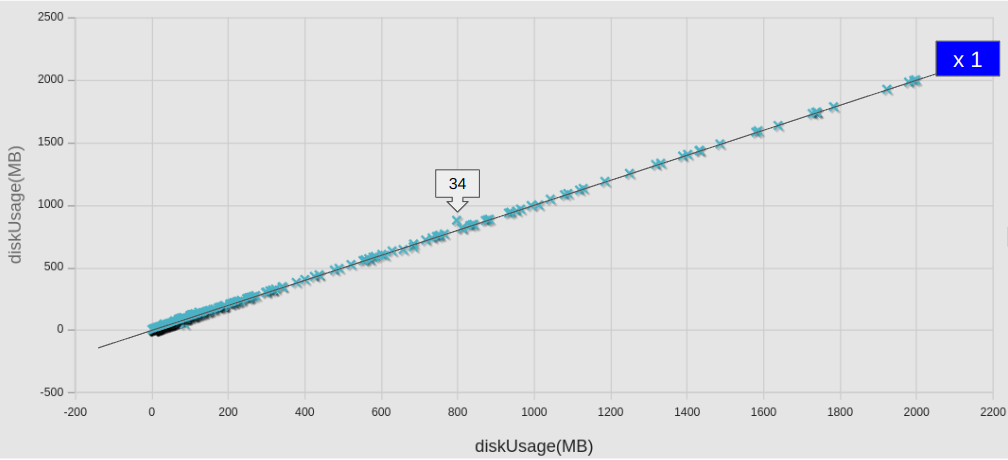
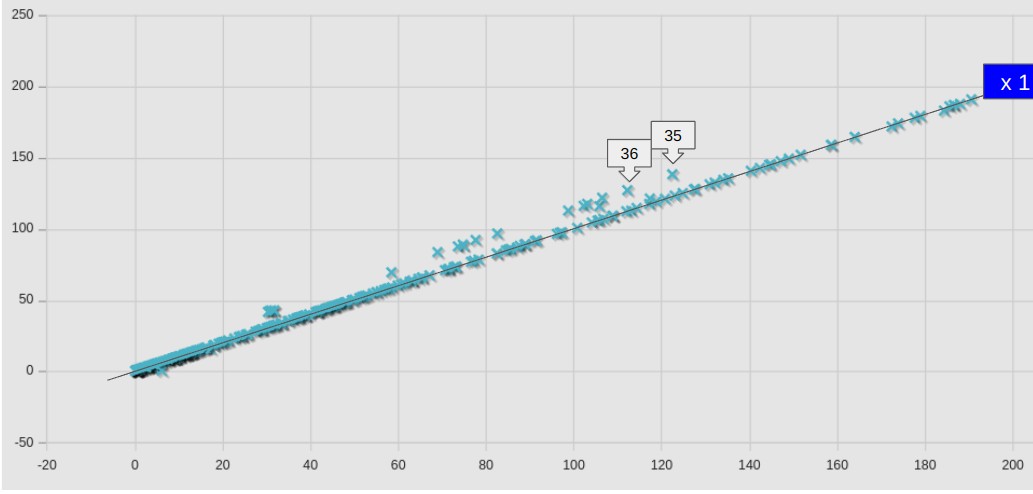
予想に反して、ほぼ完全な一致とはならなかった。旧サーバーでの結果が残っていないので、原因は不明。ただ、下の図で、No.36から左側に、ラインから明らかに外れたケースがいくつか見られるが、これらは全て adjoinOptimisationFoam/topologyOptimisation 以下のケースであった点は記しておく。
変化が大きかったケースのリスト
| No | category | solver | model | caseName | Np(New) | NP(B-New) | DU(New) | DN(B-New) | CT(New) | CT(B-New) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | incompressible | pimpleFoam | LES | planeChannel | 22 | 14 | 12.686.500 | 12.686.056 | 1.011.194 | 662.500 |
| 2 | incompressible | pimpleFoam | LES | periodicHill | 16 | 12 | 4.315.660 | 4.286.136 | 456.370 | 294.805 |
| 3 | incompressible | pimpleFoam | LES | surfaceMountedCube | 8 | 8 | 1.430.344 | 1.430.352 | 252.447 | 169.105 |
| 4 | lagrangian | DPMFoam | Goldschmidt | 1 | 1 | 4.742.492 | 4.749.624 | 92.307 | 130.472 | |
| 5 | incompressible | adjointOptimisationFoam | shapeOptimisation | motorBike | 20 | 20 | 4.015.832 | 4.004.768 | 41.392 | 16.272 |
| 6 | incompressible | pisoFoam | LES | motorBike | 8 | 8 | 13.136.832 | 13.083.128 | 33.089 | 24.383 |
| 7 | multiphase | interFoam | laminar | vofToLagrangian | 4 | 4 | 27.104.148 | 27.104.128 | 32.044 | 20.948 |
| 8 | combustion | fireFoam | LES | compartmentFire | 8 | 8 | 1.316.728 | 1.319.224 | 23.032 | 16.201 |
| 9 | multiphase | interPhaseChangeDyMFoam | propeller | 4 | 4 | 25.312.600 | 25.307.028 | 22.985 | 15.213 | |
| 10 | multiphase | interFoam | RAS | mixerVesselAMI | 6 | 6 | 20.043.852 | 20.034.324 | 22.293 | 14.739 |
| 11 | multiphase | cavitatingFoam | LES | throttle3D | 4 | 4 | 7.920.296 | 7.920.292 | 17.630 | 11.069 |
| 12 | incompressible | adjointOptimisationFoam | topologyOptimisation/monoFluidAero/laminar/3DBox | losses-mass-uniformity-SQP | 60 | 12 | 682.784 | 659.732 | 9.286 | 6.193 |
| 13 | incompressible | adjointOptimisationFoam | topologyOptimisation/monoFluidAero/laminar/3DBox | losses-mass-uniformity | 60 | 12 | 656.400 | 638.528 | 6.108 | 2.528 |
| 14 | incompressible | lumpedPointMotion | bridge | 12 | 12 | 7.721.300 | 7.715.896 | 4.930 | 2.962 | |
| 15 | incompressible | pimpleFoam | RAS | propeller | 4 | 4 | 24.166.560 | 24.160.992 | 4.670 | 3.298 |
| 16 | incompressible | pimpleFoam | LES | vortexShed | 4 | 4 | 1.735.224 | 1.735.224 | 4.379 | 3.527 |
| 17 | lagrangian | kinematicParcelFoam | drippingChair | 12 | 12 | 28.089.576 | 28.082.796 | 4.059 | 2.404 | |
| 18 | incompressible | adjointOptimisationFoam | topologyOptimisation/monoFluidAero/laminar/3DBox | losses-mass | 60 | 12 | 608.452 | 592.580 | 3.594 | 1.460 |
| 19 | lagrangian | icoUncoupledKinematicParcelFoam | hopper | 4 | 4 | 841.384 | 840.840 | 3.576 | 4.219 | |
| 20 | incompressible | simpleFoam | turbulentFlatPlate | 8 | 8 | 2.654.536 | 2.654.324 | 2.881 | 1.636 | |
| 21 | multiphase | overCompressibleInterDyMFoam | compressibleTwoSimpleRotors | 12 | 12 | 1.584.664 | 1.588.668 | 2.843 | 1.631 | |
| 22 | incompressible | adjointOptimisationFoam | topologyOptimisation/monoFluidAero/laminar/3DBox | losses | 60 | 12 | 570.392 | 556.580 | 2.221 | 893 |
| 23 | multiphase | compressibleInterFoam | laminar | depthCharge3D | 4 | 4 | 14.275.412 | 14.275.404 | 1.574 | 1.046 |
| 24 | compressible | acousticFoam | obliqueAirJet | 6 | 6 | 1.636.856 | 1.631.804 | 1.141 | 685 | |
| 25 | combustion | fireFoam | LES | smallPoolFire3D | 4 | 4 | 3.048.212 | 3.048.204 | 806 | 554 |
| 26 | lagrangian | reactingParcelFoam | airRecirculationRoom | 10 | 10 | 1.117.652 | 1.115.192 | 761 | 460 | |
| 27 | multiphase | overInterPhaseChangeDyMFoam | twoSimpleRotors | 12 | 12 | 100.748 | 100.272 | 617 | 340 | |
| 28 | incompressible | lumpedPointMotion | building | 12 | 12 | 6.339.820 | 6.317.936 | 531 | 304 | |
| 29 | incompressible | pimpleFoam | laminar | cylinder2D | 12 | 12 | 9.709.132 | 9.707.884 | 357 | 204 |
| 30 | compressible | rhoPimpleAdiabaticFoam | rutlandVortex2D | 3 | 3 | 963.568 | 962.488 | 170 | 125 | |
| 31 | incompressible | pimpleFoam | LES | decayIsoTurb | 8 | 8 | 3.819.488 | 3.819.484 | 108 | 71 |
| 32 | incompressible | simpleFoam | motorBike | 6 | 6 | 600.572 | 600.636 | 101 | 67 | |
| 33 | mesh | foamyHexMesh | flange | 1 | 1 | 220 | 232 | 1 | 20 | |
| 34 | lagrangian | MPPICDyMFoam | denseRotor2DAMI | 1 | 1 | 796.376 | 873.532 | 63 | 75 | |
| 35 | incompressible | adjointOptimisationFoam | topologyOptimisation/monoFluidAero/turbulent/1_Inlet_2_Outlet/levelSet | R_20x_NB_01 | 4 | 4 | 122.376 | 137.888 | 256 | 253 |
| 36 | incompressible | adjointOptimisationFoam | topologyOptimisation/monoFluidAero/turbulent/1_Inlet_2_Outlet/porosityBased/BP | uniformity-losses | 4 | 4 | 112.156 | 126.676 | 353 | 330 |
CPUベンチマーク
吾輩は猫である。名前はまだない。どこで生れたか頓と見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
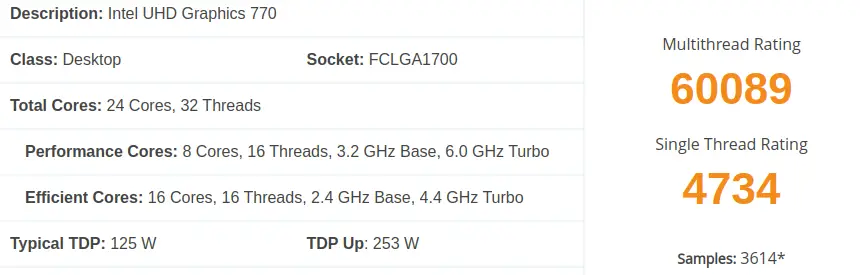

今回のAllrun(v2406)での比較では、ベンチマークの数字以上に大きな差があったと言ってよいだろう。
追試
今回のサーバーは16コア使用可能であるが、個人事業主の現実問題として常時全てのコアを計算だけに使用している訳ではない。そこで、余裕を見て最大14コアを使う設定としてAllrunを実行した。また並列分割方法が、simple, hierarchial のケースについては、サブパラメタを( 3 2 2 )として12コアを使用するとした。これらの値を変更したらどうなるか? 代表例にて調べてみた。
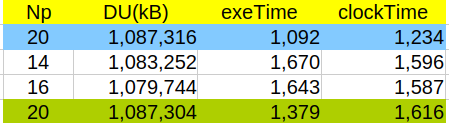
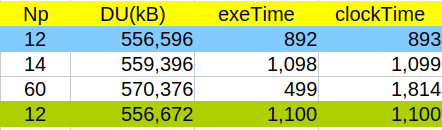

いずれの例も、水色の欄が今回の全Allrunの結果に対し、並列数を変えたことにより、計算時間が多くなっており、一般的に説明できる数字となっていない。そこで改めて最下段の計算(単独でのAllrun)をやり直してみた。こちらの数字と並列数を変えた計算(白色欄)の数字を比較すると、一般的な説明通りの結果である。全Allrunと単独Allrunの結果で、これだけ異なった理由は不明であるが、多分15コアくらいまで大丈夫でないかと考えている。
また、lagrangianのケースにおいて速度低下の要因となった下記の2ケースがある。これらは本来並列計算を想定していると考えられる(system フォルダ中に decomposedParDict が存在する)が、ケースファイル中にAllrunが存在しないので、単体計算されてしまっている。全Allrunを少しでも早く終わらせるには、並列計算するに越したことは無さそうだ。とはいえ、Allrunスクリプトを追加するなどの改変手作業に手間がかかるのでは本末転倒になってしまう。今後の参考になればと思い、並列計算もやってみた。


こちらは、並列計算することによって、如実に計算時間短縮できている。