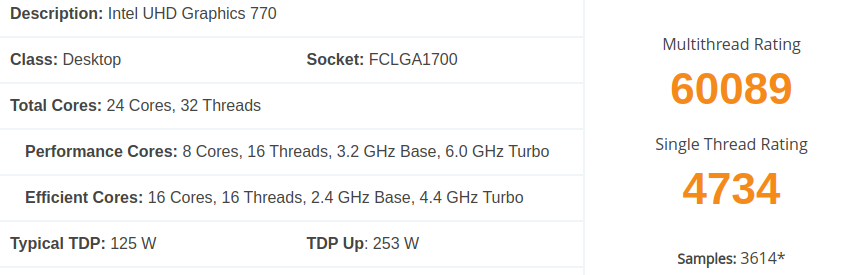
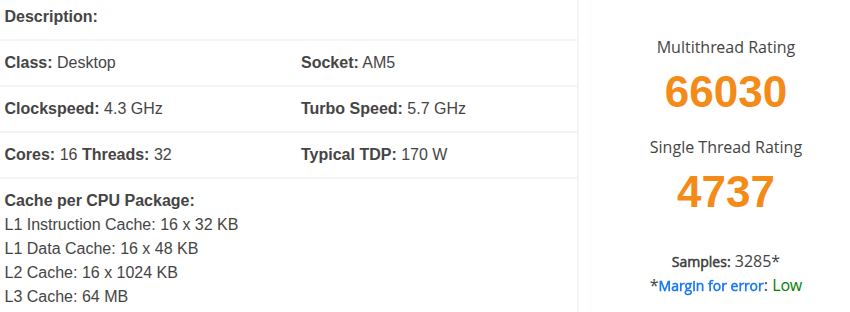
カテゴリ別ディスク使用量の比較(新旧計算サーバー)
念の為、ディスク使用量の違いについても調べたが、ほとんど同じであり、間違いなく同じ計算をしていることは確認できたと言えるだろう。
使用したSQL構文
ほとんど同じと記したが、わずかに増加しているようにも見える。この点に関しては個別ケース毎の比較で改めて調べている。
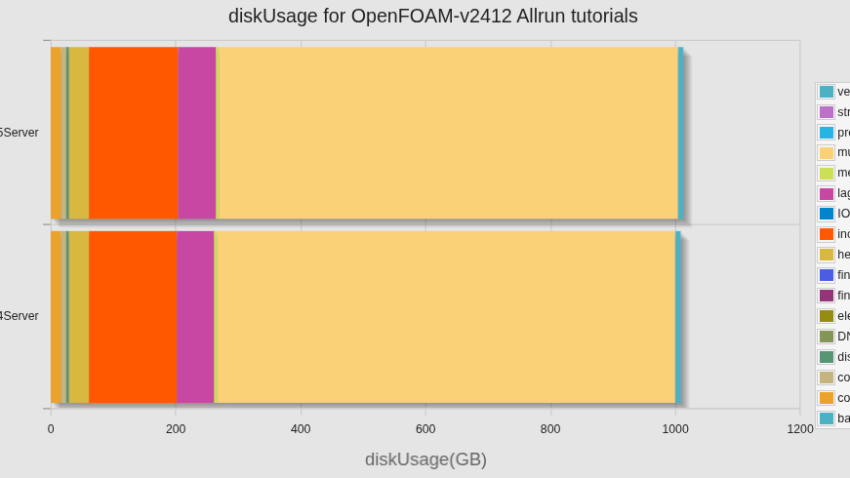
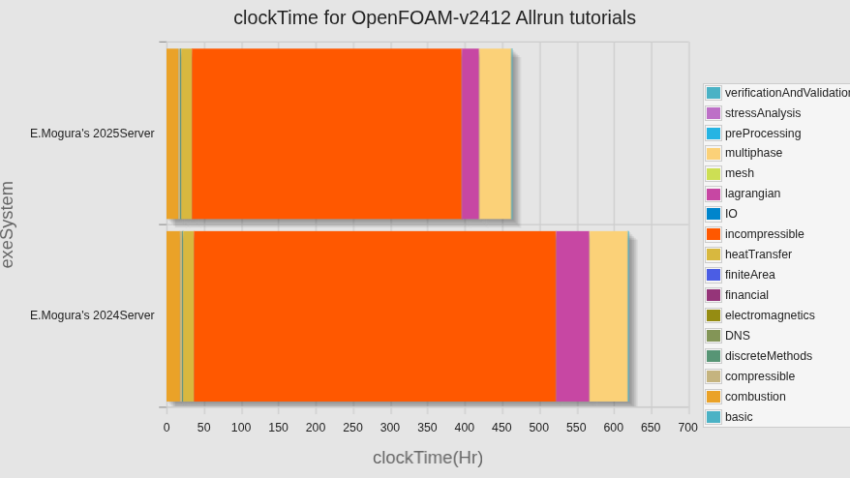
カテゴリ別計算時間の比較(新旧計算サーバー)
トータルの計算時間としては、100時間強短くなっていたが、incompressibleを除くほとんどのカテゴリで計算時間が1/2〜1/3になっているのに対して、incompressibleのカテゴリでは、計算時間が増えてしまっていた。
使用したSQL構文
並列数別計算時間の比較(新旧計算サーバー)
個別ケース毎計算時間比較(新旧計算サーバー)
並列数が8を超えるケースでの比較はあまり意味が無いので、8以下のケースについて、個別ケース毎に比較した。
使用したSQL構文
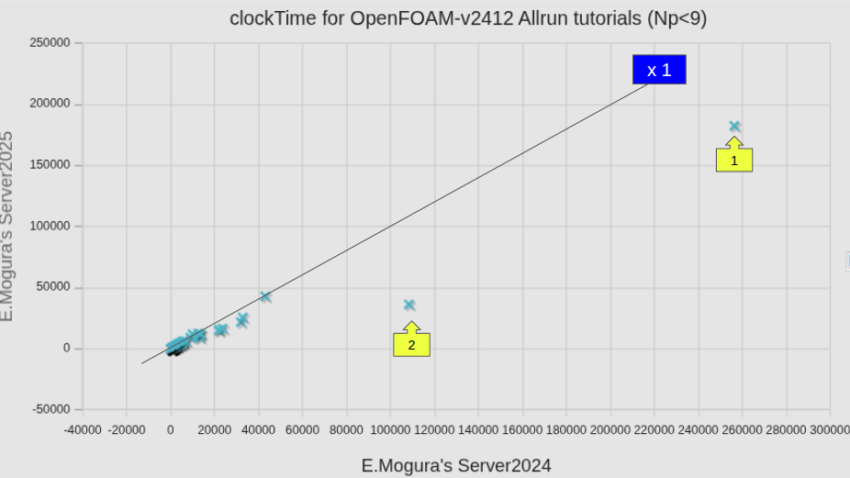
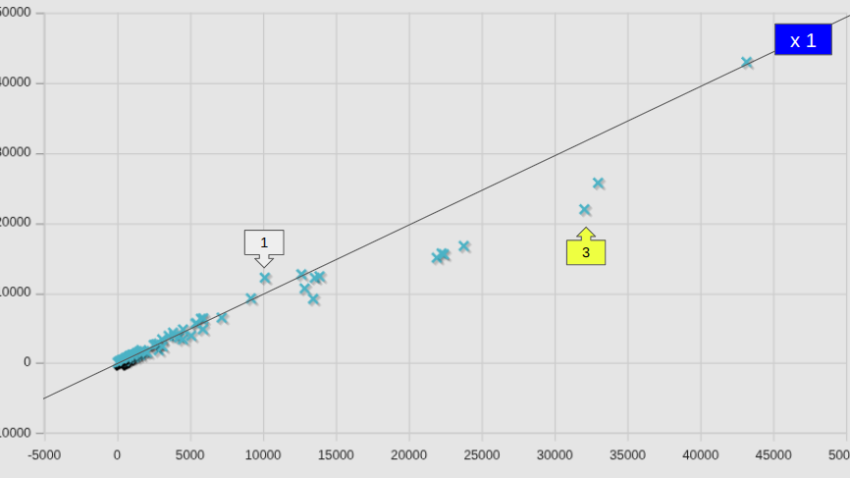
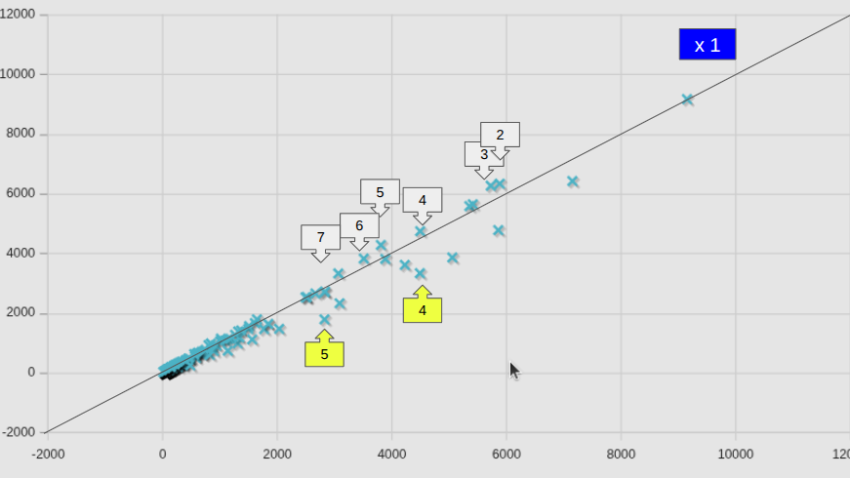
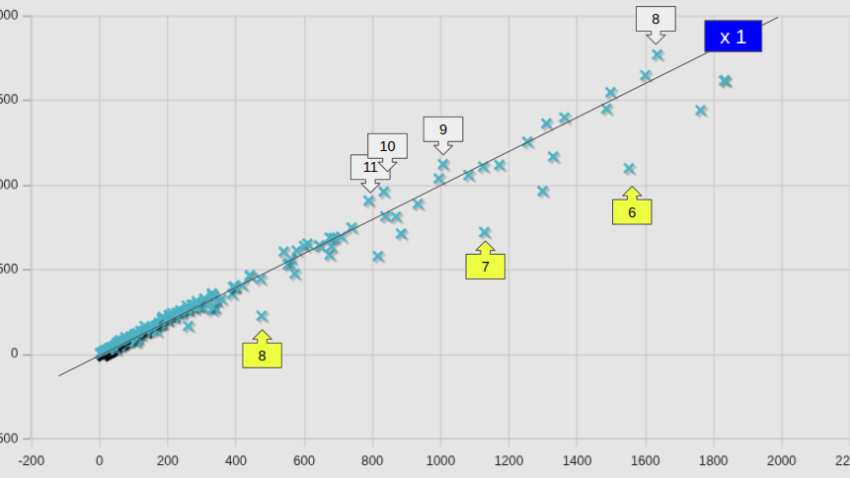
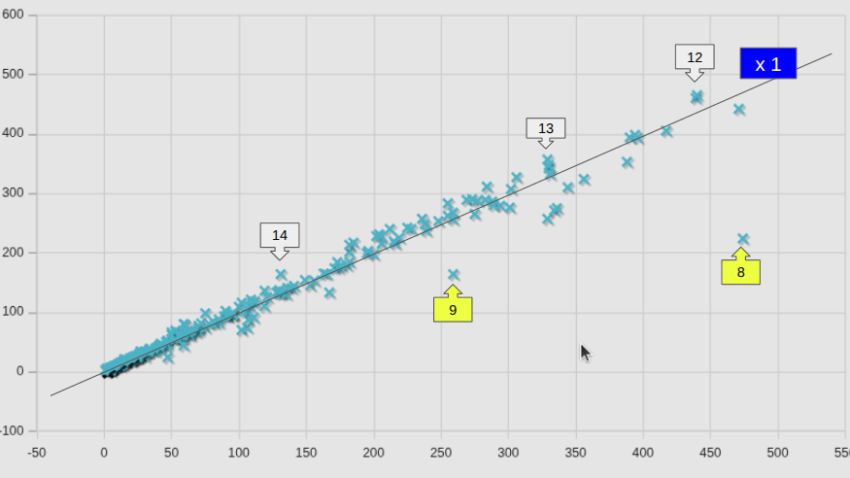
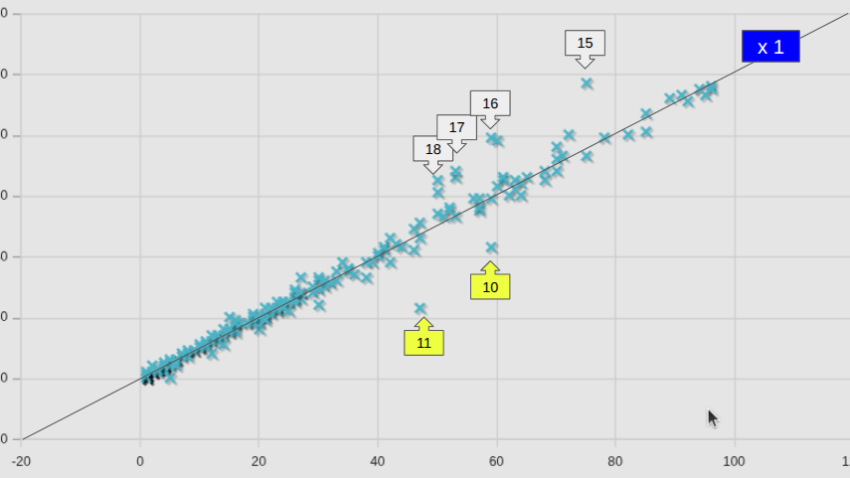
図中には、等速ライン(x1)も記してある。全平均として小さくなっている(v2406の場合は82.6%であった)ところまでは良しとしても、74.7%となるようには見えないが、これは、個別のケースで見たNo.2の低下量が大きいからであり、個別のケースで見ると、v2406の時と同様やはりかなりばらつきが大きい。
参考までに、図中の番号を付したケースの名前を、計算時間が短縮したケースと、増加したケースとを区分して記しておく。
計算時間短縮したケース(黄色番号)
- incompressible/pimpleFoam/LES/surfaceMountedCube(8)
- lagrangian/DPMFoam/Goldschmidt(6)
- multiphase/interFoam/laminar/vofToLagrangian(4)
- incompressible/pimpleFoam/RAS/propeller(4)
- incompressible/simpleFoam/turbulentFlatPlate(1)
- multiphase/compressibleInterFoam/laminar/depthCharge3D(4)
- compressible/acousticFoam/obliqueAirJet(6)
- lagrangian/MPPICFoam/Goldschmidt(5)
- verificationAndValidation/atmosphericModels/atmDownstreamDevelopment(8)
- multiphase/interIsoFoam/iobasin(8)
- multiphase/interFoam/laminar/waves/stokesII(2)
計算時間増加したケース
- multiphase/interFoam/laminar/waves/irregularMultiDirection(2)
- lagrangian/sprayFoam/aachenBomb(1)
- combustion/reactingFoam/laminar/counterFlowFlame2D_GRI(1)
- combustion/reactingFoam RAS/SandiaD_LTS(1)
- lagrangian/icoUncoupledKinematicParcelFoam/hopper(4)
- incompressible/ pimpleFoam/RAS/wingMotion(4)
- discreteMethods/dsmcFoam/supersonicCorner(4)
- combustion/reactingFoam/laminar/counterFlowFlame2D_GRI_TDAC(1)
- multiphase/MPPICInterFoam/twoPhasePachuka(4)
- incompressible/overPimpleDyMFoam/twoSimpleRotors(1)
- discreteMethods/molecularDynamics/mdEquilibrationFoam/periodicCubeWater(1)
- combustion/reactingFoam/laminar/counterFlowFlame2DLTS_GRI_TDAC(1)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/1_Inlet_2_Outlet_Dual_Bottleneck/losses-mass-30-70(4)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/turbulent/1_Inlet_2_Outlet/levelSet/R_10x_NB_02(4)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/1_Inlet_2_Outlet/porosityBased/R_10x-init(4)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/1_Inlet_2_Outlet/porosityBased/R_20x(4)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/1_Inlet_2_Outlet/levelSet/R_10x_NB_02x(4)
- incompressible/adjointOptimisationFoam/topologyOptimisation/monoFluidAero/laminar/1_Inlet_2_Outlet/levelSet/R_10x_NB_01x(4)
リスト中、太字で記したのは、v2406での新旧サーバー比較記事でも抽出されたものである。
計算時間が短縮したケース中、2番と8番は、v2406の比較ではなかったものであり、大きく低減したのは、並列計算の効果である(新サーバーでは単体計算であった)。
また、計算時間の増加したケースのリスト中、15番以降は、adjoiintOptimizationFoamソルバーを使ったケースであり、図を見ると抽出した番号の近くには、他にも多くのケースのあることがわかる。これらもやはり同一ソルバーのケースであった。
個別ケース毎ディスク使用量比較(新旧計算サーバー)
カテゴリー別ディスク使用量を比較した場合、ほぼ同一と記したが、わずかな違いがあるようにも見られた。そこで個別のケース毎にも調べてみた。
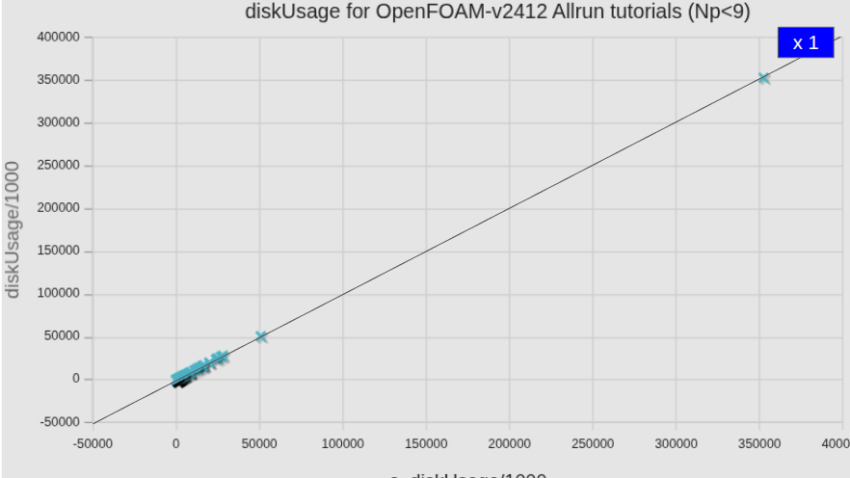
全体グラフで見ると、やはり違いはわからないが、以下のように詳細化して明確になった。
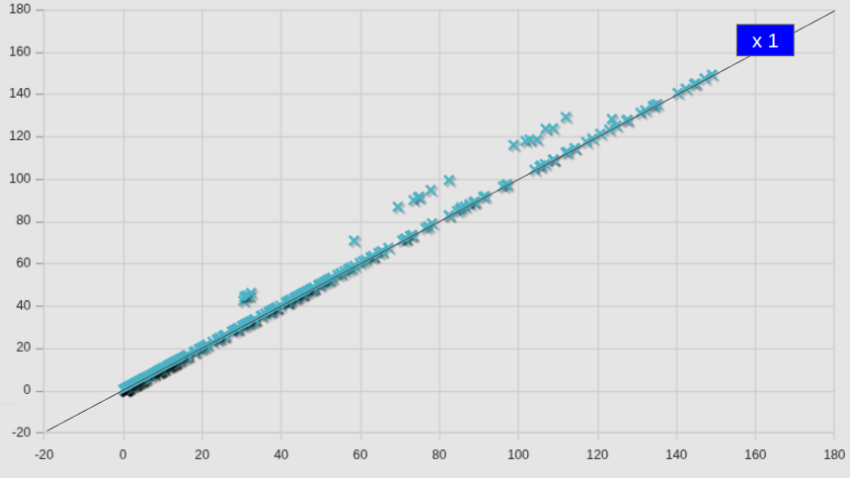
明らかに変化なし(x1)のラインからオフセットしたケースが多く存在していた。これらのケースは、ほとんどが、前項の最後の方に記したadjoiintOptimizationFoamソルバーを使ったケースであった。
つまりこれらのケースは新々サーバーにおいて、新サーバーで実行した場合より、余分な計算を実行しており(逆に言うと新サーバーで計算していない部分があった)、その為計算時間も増えたと解釈できる。
新サーバーでの計算ログは残っていないので推察でしかないが、これらのケースの実行内容を調べたところ、思い当たるふしも出てきた。これらのケースのAllrunは以下の内容となっている。