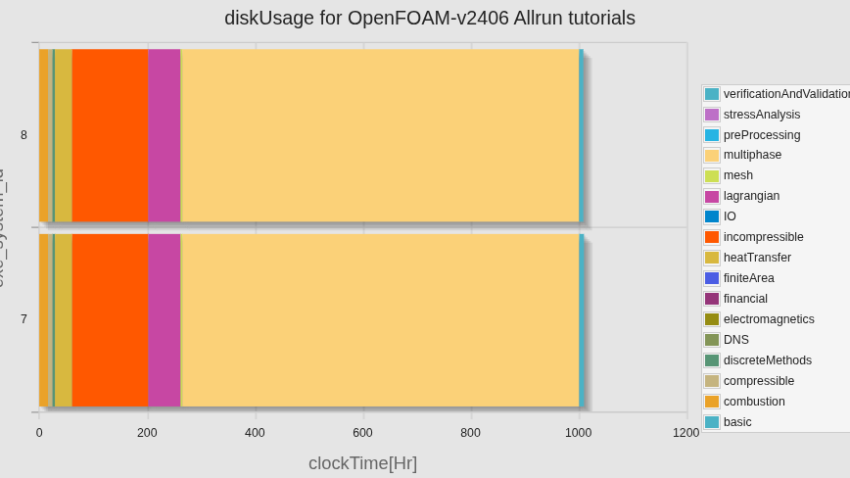
カテゴリ別ディスク使用量の比較(新旧計算サーバー)
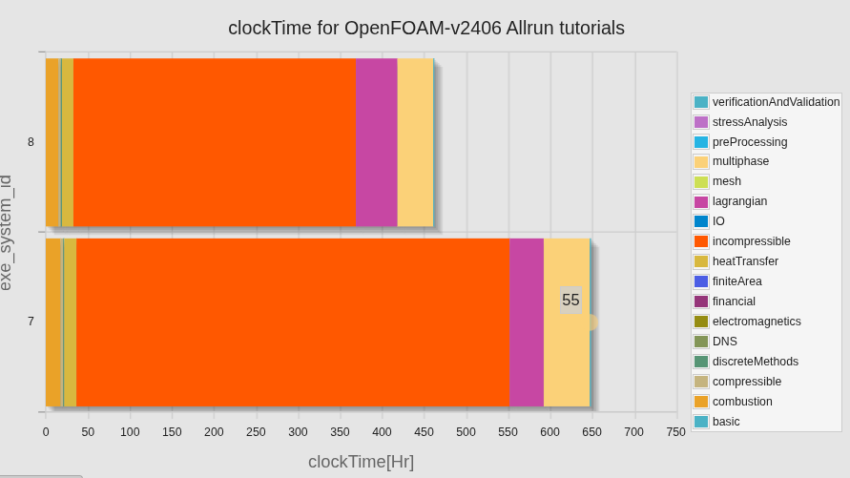
カテゴリ別計算時間の比較(新旧計算サーバー)
トータルの計算時間としては、100時間強短くなっていたが、incompressibleを除くほとんどのカテゴリで計算時間が1/2〜1/3になっているのに対して、incompressibleのカテゴリでは、計算時間が増えてしまっていた。
使用したSQL構文
並列数別計算時間の比較(新旧計算サーバー)
個別ケース毎計算時間比較(新旧計算サーバー)
並列数が8を超えるケースでの比較はあまり意味が無いので、8以下のケースについて、個別ケース毎に比較した。
使用したSQL構文
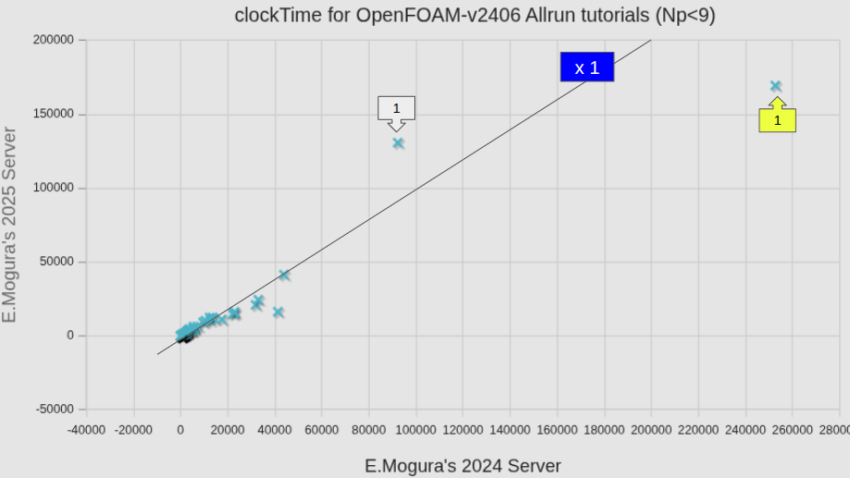
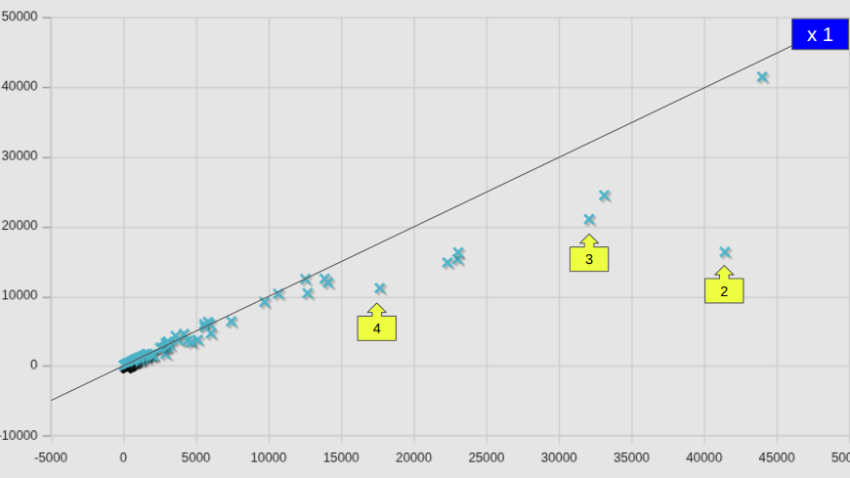
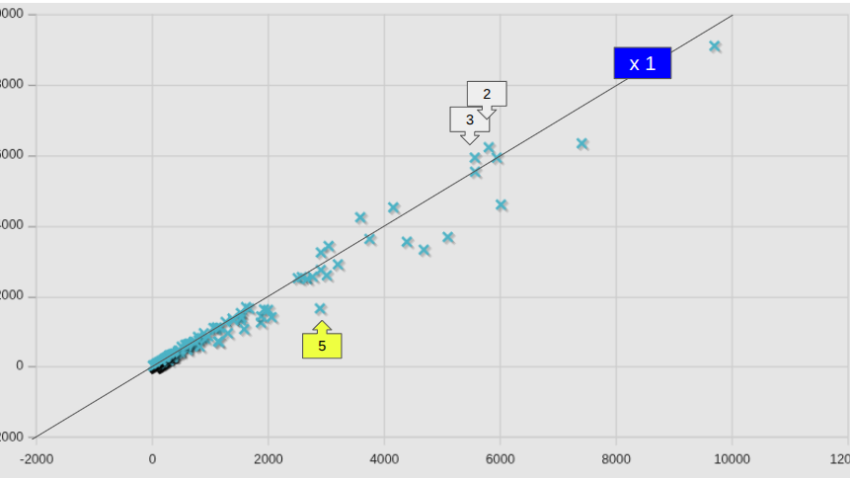
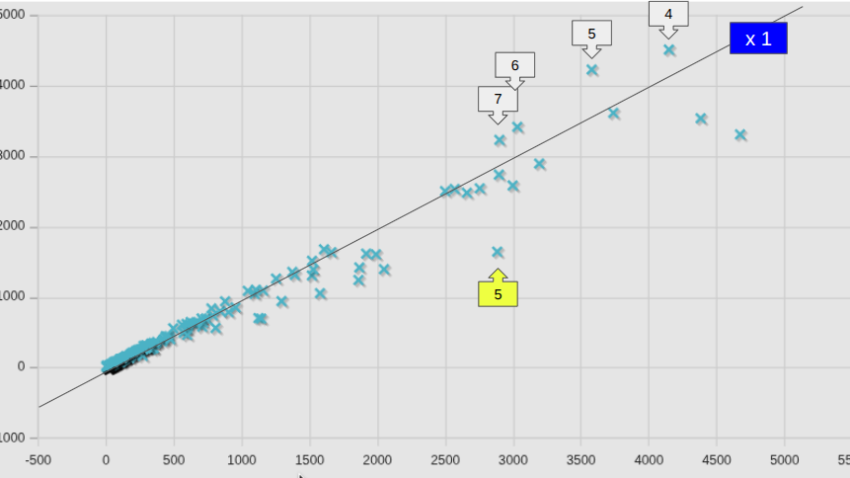
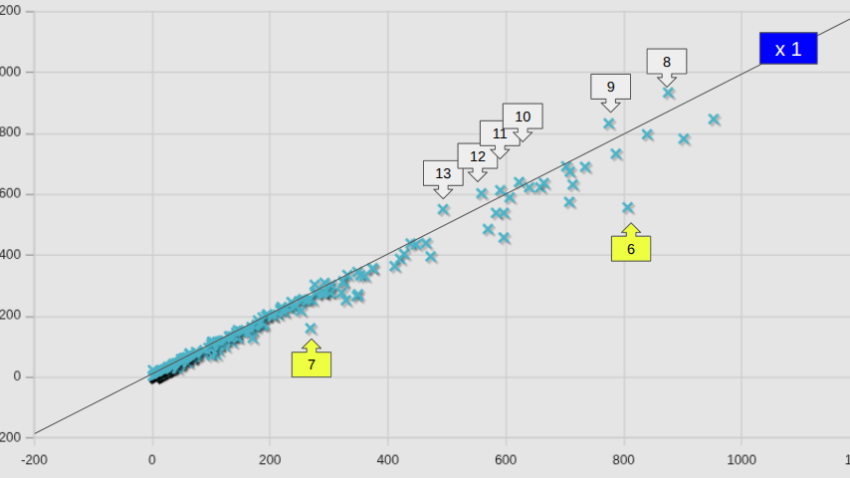
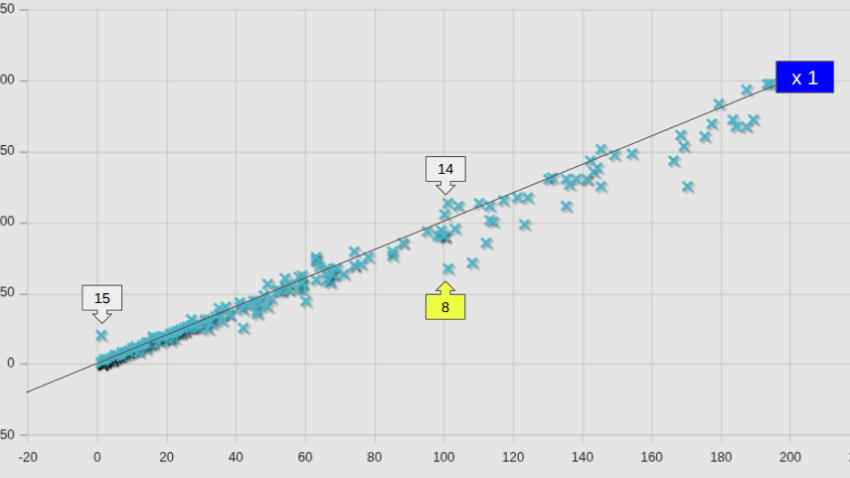
図中には、等速ライン(x1)も記してあるが、全平均として82.6%となっていた数字は凡そ納得できそうではある。しかし個別のケースで見ると、かなりばらつきが大きいこともわかった。
参考までに、図中の番号を付したケースの名前を、計算時間が短縮したケースと、増加したケースとを区分して記しておく。
計算時間短縮したケース(黄色番号)
- incompressible/pimpleFoam/LES/surfaceMountedCube(8)
- incompressible/adjointOptimisationFoam/shapeOptimisation/motorBike(20)
- multiphase/interFoam/laminar/vofToLagrangian(4)
- multiphase/cavitatingFoam/LES/throttle3D(4)
- incompressible/simpleFoam/turbulentFlatPlate(1)
- combustion/fireFoam/LES/smallPoolFire3D(4)
- compressible/rhoPimpleAdiabaticFoam/rutlandVortex2D(3)
- incompressible/pimpleFoam/LES/decayIsoTurb(8)
計算時間増加したケース
- lagrangian/DPMFoam/Goldschmidt(1)
- lagrangian/sprayFoam/aachenBomb(1)
- combustion/reactingFoam/laminar/counterFlowFlame2D_GRI(1)
- combustion/reactingFoam/RAS/SandiaD_LTS(1)
- lagrangian/icoUncoupledKinematicParcelFoam/hopper(4)
- multiphase/interFoam/RAS/DTCHullMoving(8)
- discreteMethods/dsmcFoam/supersonicCorner(4)
- incompressible/overPimpleDyMFoam/twoSimpleRotors(1)
- discreteMethods/molecularDynamics/mdEquilibrationFoam/periodicCubeWater(1)
- lagrangian/reactingParcelFoam/verticalChannel(1)
- verificationAndValidation/schemes/nonOrthogonalChannel(1)
- compressible/overRhoPimpleDyMFoam/twoSimpleRotors(1)
- lagrangian/MPPICFoam/Goldschmidt(1)
- discreteMethods dsmcFoam/freeSpaceStream(4)
- mesh/foamyHexMesh/flange(1)