5. Plot ワークベンチを使った post 処理
5.1. 単グラフの自動作成
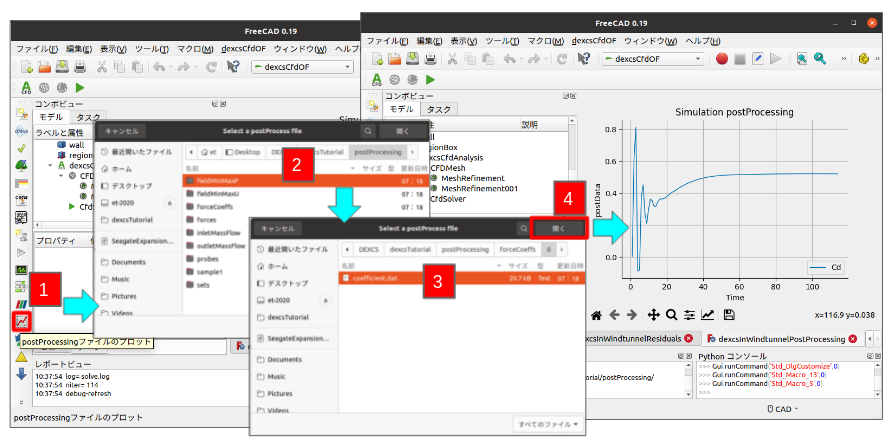
既に3-1.でログファイルを対象に残渣図を描けているので、まずはこれをベースにプロット対象を、ログファイルでなく、postProcessingフォルダ中の後処理データを対象に単グラフ(横軸に最初の数値カラム、縦軸に2番目の数値カラム)作成用のマクロを作成することとした。何はともあれ、これが出来ないことには、現行のDEXCSランチャーで、JGPを使って作成できている複合グラフの作成も覚束ないことになってしまう。
ほぼ1日間の試行錯誤を経て、図54.に示すような手順で、postProcessingフォルダ中、setフォルダ(vtkファイルが収納されている)を除くすべてのファイルに対して、単に![]() 〜
〜![]() のマウス操作で、プロットしたいファイルを選択するだけで、それなりのプロット図を描けるようになったことを確認した。postProcessingフォルダのファイル内容は、それぞれ異なり、特にデータ系列がたくさんある場合、系列を選択してプロットしたいところであるが、今の所、第1列をX軸に、次に現れる数値列をY軸にプロットするようにしただけである。ファイルの中に記してあるコメント行読み取ってそれぞれの列に相応するコメントをX軸ラベルと凡例の名前として表示するようにしている。
のマウス操作で、プロットしたいファイルを選択するだけで、それなりのプロット図を描けるようになったことを確認した。postProcessingフォルダのファイル内容は、それぞれ異なり、特にデータ系列がたくさんある場合、系列を選択してプロットしたいところであるが、今の所、第1列をX軸に、次に現れる数値列をY軸にプロットするようにしただけである。ファイルの中に記してあるコメント行読み取ってそれぞれの列に相応するコメントをX軸ラベルと凡例の名前として表示するようにしている。
第1列をX軸にするのはよいとして、単純にY軸を第2列としなかったのは、たとえば、functionの、
type fieldMinMax;で作成されるポストデータは、
# Field minima and maxima
# Time field min location(min) processor max location(max) processor
1 p 0.000000e+00 (1.000000e+00 -5.103853e+00 -1.403853e+00) 1 4.345071e+00 (-6.866991e+00 -3.964603e+00 4.443966e-02) 0
2 p 0.000000e+00 (1.000000e+00 -5.103853e+00 -1.403853e+00) 1 9.219603e+02 (-6.867227e+00 -2.440362e+00 -2.634384e-01) 0
3 p -5.074832e+01 (-3.359984e+00 -3.414010e+00 6.110496e-01) 1 1.860776e+02 (-4.972372e+00 -3.691786e+00 1.827246e-01) 0
となっており、第2列が数字でないこともあるからである。
また、type probes: で作成されるデータは、
# Probe 0 (0 -3.5 0.2)
# Probe 0
# Time
1 0.369279
2 129.815
3 -6.30889となっており、この場合は凡例名を上記ロジックでは読み取れないという若干の問題は残されている。
初期残渣を表示するのに使ったマクロは、runPlotWather.pyであったので、これを雛形にrunPlotPost.pyを作成した。このマクロ(プログラム)の基本的な処理の流れは、
- プロット対象データの取得
- 作画用インスタンス作成
- プロット用のデータ抽出処理
- 作画インスタンスに抽出データを渡す
- 作画インスタンスの更新(refresh)
であり、3-1.で記したように、作画インスタンスを作成するプログラムは自動更新の仕組みを有しているが、ログファイルの更新を監視する仕組みが(今の所)存在しないので機能しない。というか、この機能を残したままプログラムを改変しようとすると、プログラムのデバッグがなかなかに困難であった。そこでここでは、作画インスタンスを作成するモジュールでは自動更新させない仕組みに改変し、更新(処理の流れの第5項目)は、マクロ本体にて実施することにした。また、これは、3-1.で作成した初期残渣表示マクロについても同じ事が言えるので、こちらも同様に変更しておいた。つまり、dexcsCfdResidualPlot.py にて、以下の3行をコメントアウトし、
#self.Timer = QtCore.QTimer()
#self.Timer.timeout.connect(self.refresh)
#self.Timer.start(2000)一方、呼び出す側の、runPlotWatcher.py では、
def _plotResidual(logFile, niter):
print("log=",logFile)
f=open(modelDir+"/"+logFile)
loglines = f.readlines()
#f.close()
process_output(loglines, niter)
#residualPlot.updateResiduals
residualPlot.updated = True
residualPlot.refresh()緑字部分をコメントアウトして、以下の朱字部分を追加した。なお、これにより、グラフが表示されるまでの待ち時間が少なくなった。
基本的に初期残渣を表示するのに使った dexcsCfdResidualPlot.py を雛形に、dexcsCfdPostPlot.py にて、まずPlotモジュールを使って作画用のインスタンスを作成する。dexcsCfdPostPlot.pyの内容は、以下の通りである。
import FreeCAD
from freecad.plot import Plot
class PostPlot:
def __init__(self):
self.fig = Plot.figure(FreeCAD.ActiveDocument.Name + "PostProcessing")
self.updated = False
self.postX = []
self.postY = {}
def updatePosts(self, labelX, postX, postY):
self.updated = True
self.labelX = labelX
self.postX = postX
self.postY = postY
def refresh(self):
if self.updated:
self.updated = False
ax = self.fig.axes
ax.cla()
ax.set_title("Simulation postProcessing")
ax.set_xlabel(self.labelX)
ax.set_ylabel("postData")
for k in self.postY:
if self.postY[k]:
x = self.postX
y = self.postY[k]
ax.plot(x, y, label=k, linewidth=1)
ax.grid()
ax.legend(loc='lower right')
self.fig.canvas.draw()残渣プロットの場合は、グラフにデータを渡す部分で、
ax.plot(self.residuals[k], label=k, linewidth=1)となっていた。この場合、横軸の指定は特になかったということである。無ければ、単純に1から増える自然数で補完されているということであろう。これをステップ数で読み替えれば済んだのであった。ここで考えているポスト処理は、横軸がステップ数以外のもの(たとえばサンプリングデータ)にも対応したいので、横軸を任意に変更したかった。横軸を追加して指定する方法については、試行錯誤の結果、単純に引数を追加してやれば良いということであった。
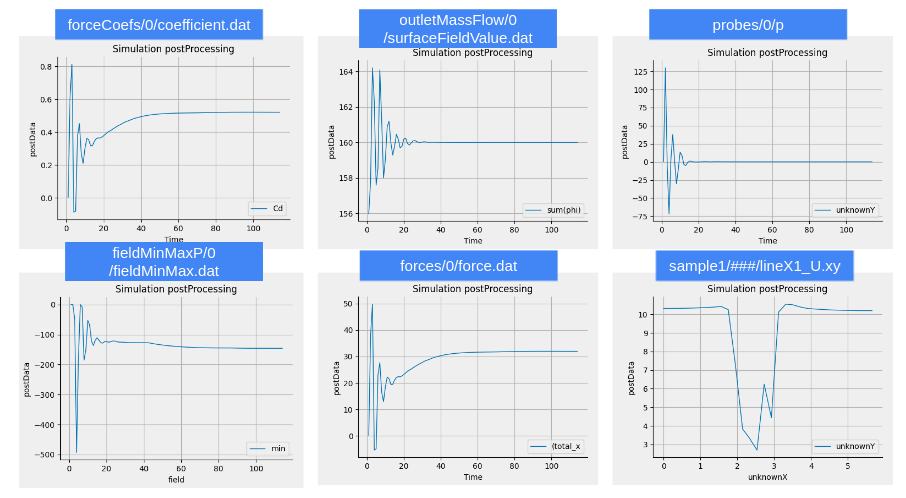
結局、dexcsCfdResidualPlot.pyで使っていたresidualsという変数を、postYに変更。横軸を追加するに際して、朱字部分が追加されたという見方をしてもらえればよい。また、dexcsCfdResidualPlot.pyでは、対数軸表示に関連して、細々とした設定が随所にあったが、それらの部分は全て削除し、いわばPlotモジュールにデータを渡して、デフォルト設定でグラフを描かせるようにした。有り難いことに、このデフォルト設定で、通常のGNUPLOTに比べれば十分に美しいと思えるのだが、いかがであろう?(図55)
一方、これを呼び出す側(runPlotPost.py)も、シンプルになった。メインルーチンは以下の通りである。
(fileName, selectedFilter) = QtGui.QFileDialog.getOpenFileName( None, _("Select a postProcess file"),modelDir + "/postProcessing")
name = os.path.splitext(fileName)[0]
if name != "":
f = open(fileName,"r")
lines = f.readlines()
f.close()
print("postProcessing=",f.name)
PlotValue = []
postPlot = PostPlot()
_plotPost(lines)ポスト処理対象のファイルの内容を一気に読みとって、下から2行目で作画用インスタンス作成、最後の一行でデータを渡しているだけである。def _plotPost(postlines)の内容は、
def _plotPost(postlines):
process_output(postlines)
postPlot.updated = True
postPlot.refresh()データをprocess_output(postlines) 経由でインスタンスに渡すのと、画面インスタンスを更新しているだけ。データを渡す本体は、postProcessingデータをカラム処理して、プロット出力用に、
def process_output(text):
# 単グラフの自動表示
# 最初に見つかった数値列をX軸に、次に見つかった数値列をY軸表示
for line in text:
line = line.replace('(','')
line = line.replace(')','')
# 最終行で数値カラムを探す
split = line.split()
key=[]
ikey=0
for index in split:
if is_num(index):
key.append(ikey)
ikey = ikey + 1
niter = 0
postX = []
#print(key)
for line in text:
split = line.split()
#print(split)
if split[0] != "#" :
postX.append(float((split[key[0]].replace('(','')).replace('),','')))
PlotValue.append(float((split[key[1]].replace('(','')).replace('),','')))
niter = niter +1
else:
#数値行でない行の、最終行を取得しておく
# これをラベルや凡例にする(の場合が多い)
splitTitle = split
#非数値最終行から、X軸ラベルや凡例名を切り出す
#key[1]列目⇒X軸タイトル
#key[2]列目⇒凡例名
#見つからなかったら "unknown"
try:
labelX = splitTitle[key[1]]
except:
labelX = "unknownX"
try:
legend = splitTitle[key[2]]
except:
legend = "unknownY"
if legend == "unknownY":
try:
legend = splitTitle[key[1]+1]
except:
legend = "unknownY"
if niter > 1:
postPlot.updatePosts(labelX, postX, OrderedDict([
(legend, PlotValue)]))
else:
message = (_("there in no data for plotting."))
ans = QtGui.QMessageBox.critical(None, _("check postProcessing data"), message, QtGui.QMessageBox.Yes)labelX, postX, OrderedDict([(legend, PlotValue)]という3つのパラメタを作成している。ここで、カラム処理の基本は、行単位で見て先頭に#のある行はコメント行で、そうでない行がデータ行となっているので、データ行はスプリット関数でカラム毎に分割できるのだが、ポスト処理データによっては書式が微妙に異なっているので、実際にプログラミングをする際にいくつか例外処理が必要であった。その他注意点もあって、要点を以下に取り纏めておく。
- ポスト処理データは基本的に数値列だが、ベクトルデータは括弧付きで、しかも数値との間のスペース無しで表示されるのでスプリット処理しただけでは数値として認識されない。
- 上記括弧を取り除いたとしても、それが数値なのかどうかを適切に判断できる標準関数(たとえば、isNumなど)は存在しないので、数値に変換できるかどうかを調べる関数(is_num)を作成する必要があった。といっても、公開されているものを借用しただけであるが(以下の関数)。
def is_num(s):
#文字列が数値に変換できるか判定 https://note.nkmk.me/python-str-num-determine/
try:
float(s)
except :
return False
else:
return True- スプリット処理しただけでの状態は文字列で、これを単純にプロット用のデータ系列(postX,postValue)にappendするだけでも、グラフを作成してくれるが、単純に勾配1の直線にしかならない。数値化(float)してappendする必要があった。
- 横軸データは、ラベル(labelX)と数値列(postX)を別変数として定義しているが、縦軸は辞書配列(OrderedDict)として、変数の一系列として収納している。これは多グラフへの拡張も想定している為である。
なお、本プログラムはこのままでは、ポスト処理データとして意味のある内容が入っているかどうかを確認する程度の用途にしか使えないであろう。最低限でもカラムを指定して表示できるようにする必要はある。また先に記した凡例名の読み取り不全の問題もある。そこまで作り込んでから公開としないで、ある意味中途半端な状態で公開しているのは、まずは可能性はありそうだとの感触が得られたので、とりあえずここまでのノウハウを取り纏めておいた方が良いであろうという点と、当面のリリースあるいは最終ゴールとして、どこまで作り込むかのイメージを明らかにしてから取り組んだ方が良いであろうとの判断があったからである。