5.2. ポスト処理イメージと実装方針
現時点で、想定しているポスト処理のGUIイメージ(ここまで出来たら良いなぁ)を図56.に示す。
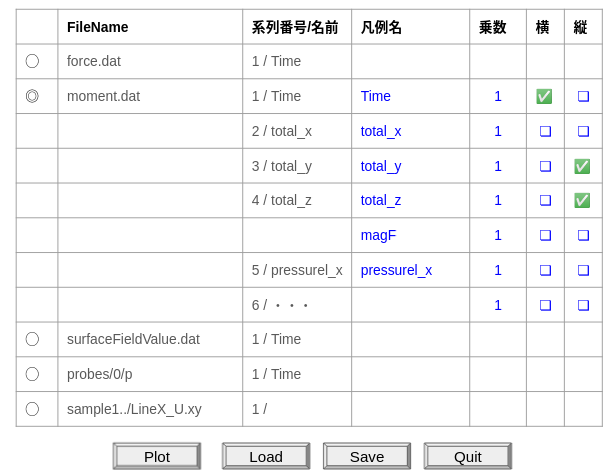
起動すると、postProcessingフォルダ中に収納されている(.vtk)以外の全ファイルがリストアップされ、表示したいファイルのトグルをオンにすると、全カラムリスト(+アルファ)が展開表示される。系列番号/名の欄には、対象ファイル中に記されたコメント行から取得されたテキストが表示され、デフォルトではこれがそのまま凡例名の欄に転記して表示されているが、この欄は編集可能にしておく。乗数欄はデフォルトで[1]つまりそのまま表示され、ここも編集可能にしておき、たとえば[-2]とすれば、-2を掛けた値がプロットされるということである。また横、縦の欄は横軸、縦軸として表示対象を指定するもので、横は1つしか指定できない。縦は複数指定可能である。(+アルファ)というのは、ベクトルデータが存在する場合に、その絶対値を表示できるよう使用する行として追加挿入される仕組みとしておくものである。
下段の4つのボタンの役割については、説明するまでないであろう。
またこれらのイメージが、実際に作り込んで使ってみてという経験を経て、変化していく事は大いに考えられる。したがって、あまりこのイメージには拘泥しないで、先にボタンを押した時に実行される機能を作り込むというか、作れないことには先へ進めないので、そのあたりをつける事を当面の課題としたい。
具体的には、上記の画面状態を設定ファイルとして保存することになるので、実際の具体例で仮の設定ファイルを作成しておく。この設定ファイルを読み込んで、その書式も今の所未定だが、書式の設定も含めて所定のグラフ画面を表示できるようになるかどうかの確認が必要であろう。実際の具体例としては、これまでDEXCS標準チュートリアルでサンプル表示していたプロット例があるので、これらに対してそれぞれ個別の設定ファイルを手作業で作成、これを読み込んで、Plotモジュールを使ったグラフ表示で再現できるようにすれば良さそうだ(第1ステップ)。最低限ここまで出来ていれば、DEXCS2021としてリリースする事には問題無いと思っている。
第2ステップはGUI画面の作成で、postProcessingフォルダ中のデータが意図した通りに表示できるようにすること。これを、DEXCS標準チュートリアル以外の問題でも確認できれば良いであろう。
最後の第3ステップとして、操作ボタンへの関数割り付けということになりそうだが、[Plot]ボタンを押した時の関数には、第1ステップのコードをかなり流用できるであろうし、書式が確定しておれば[Save]や[Load]ボタンを押した時の関数の構築も容易だろうと思っている。
5.3. ステップ1: 設定ファイルに基づく複グラフ作成
完成した第2ステップの複グラフ作成イメージを図59.に示す。
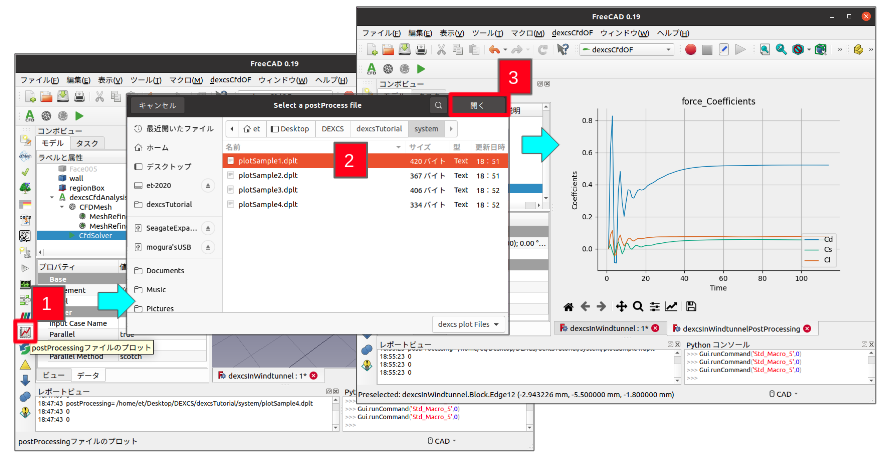
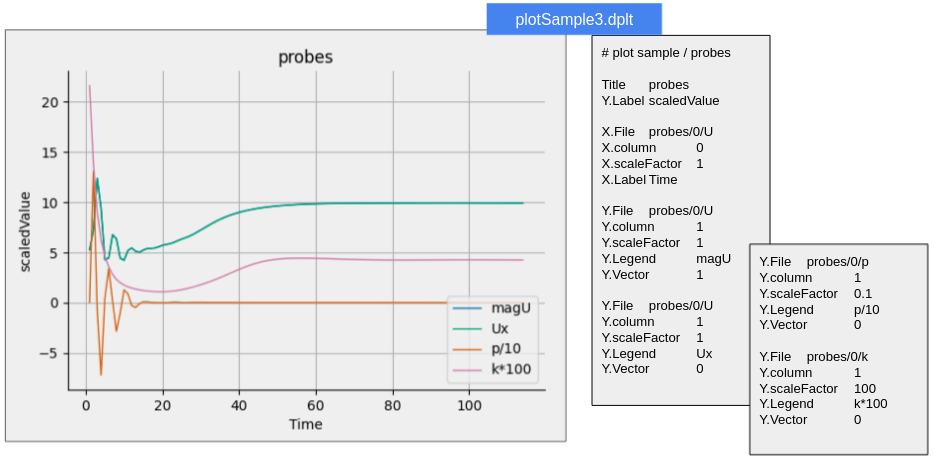
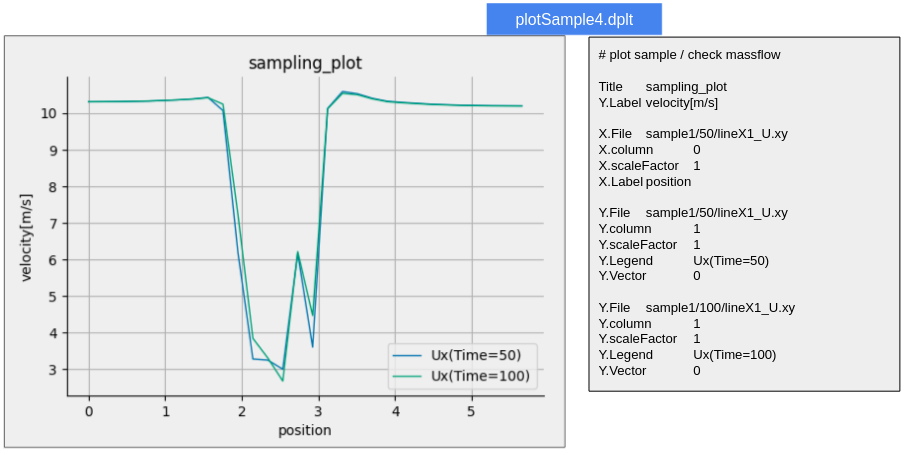
DEXCS標準チュートリアルでは、事前に用意した4つのプロット用設定データ(*.dplt)がsystemフォルダ下に収納されており、どれかを選択すれば相応のプロットサンプルが出力されるというものである。4つのプロットサンプルは、これまでDEXCSチュートリアルで例示してきたサンプルをほとんどそのまま再現するようにした。
設定ファイルはテキストファイルであり、その内容を見れば容易に処理内容を推察できるものと思われる。
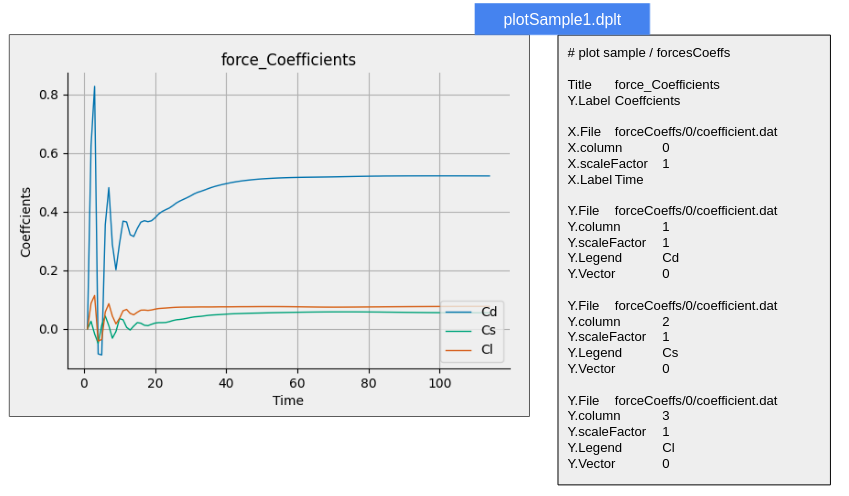
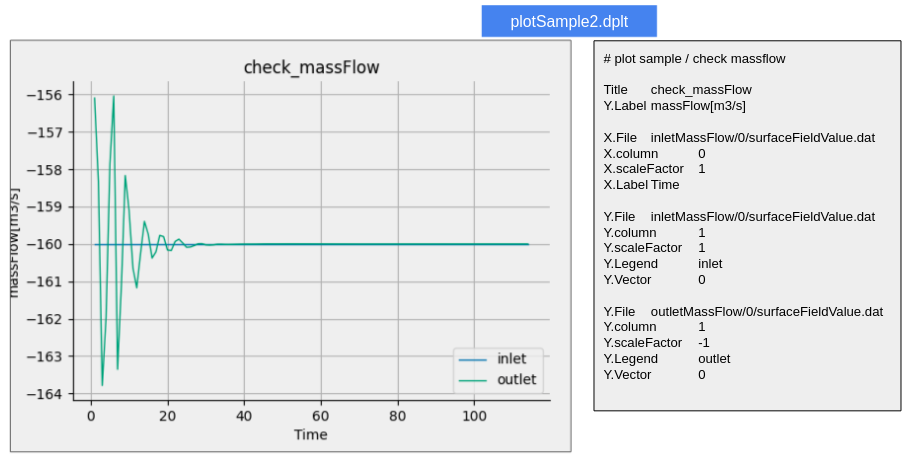
実は、当初この書式で実装していって、DEXCS標準チュートリアルにおいては、問題無く動作していたのだが、他の問題に適用してみたところ、大きく2つの問題があることが判明した。すなわち、
- 異なる横軸系列の混在グラフを描くことができない。
- 横軸系列で同一点に複数データが存在した時にエラーとなってしまう。
第1項目に関しては、データ系列の指定を各系列に対して個別に指定するようにすれば良いのではないかと思われたのであるが、見かけ上の複グラフは作成できたのであるが、よく見ると縦軸が横軸の期待した点にプロットされない。図64に簡単なプロット例を示すが、本来左側に示すようにプロットされるべきところが、右側のようにプロットされてしまった。右側の上と下では、プロットの系列の指定順序を入れ替えただけである。
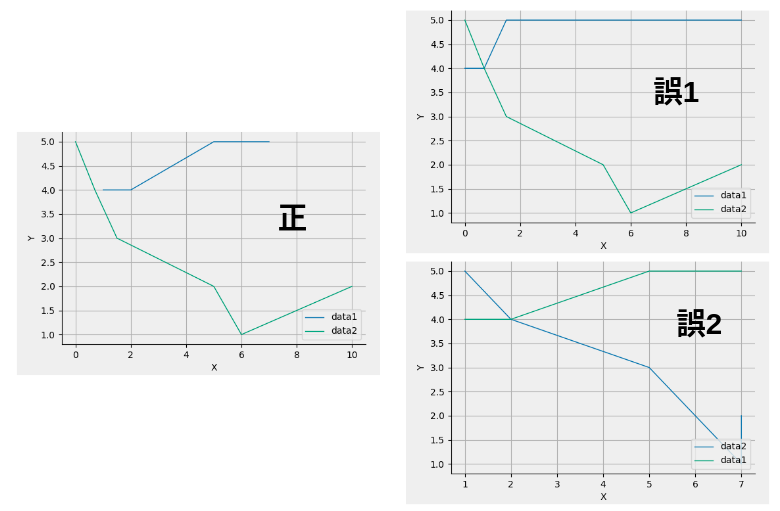
どちらか一方のグラフは正しく表示されているが、もう一方のグラフは横軸が一致していおらず、単に順列でプロットされているかの様相であった。実際のプロットアルゴリズムまで調べた訳ではないが、対応策として、全グラフに共通な横軸系列を作成し、その共通系列に対して、各々のデータを再配置しててやれば良いことがわかった。
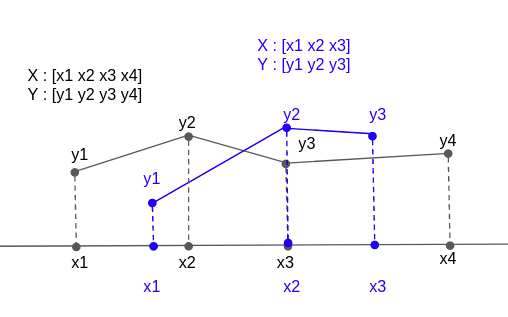
図67.に模式的示しておいたが、黒色のデータ系列と青色のデータ系列が存在した場合に、まず共通の横軸系列
[x1 x1 x2 x3 x2 x3 x4]を作成する。ここでデータは当然、小さいものから大きくなるように並べられ、図ではx3とx2の大小関係が微妙であるが識別できるものであれば、上のように作成するが、全く同一の場合は重複値として削除しておく。プログラムで書くと以下のようになった。
for k in range(len(Y_File)) :
postX = process_column_X(X_File[k], X_column[k], X_scaleFactor[k])
PostsX.append(postX)
if Y_Vector[k] == "1":
PlotValue = process_column_vector(Y_File[k], Y_column[k], Y_scaleFactor[k])
else:
PlotValue = process_column(Y_File[k], Y_column[k], Y_scaleFactor[k])
PostsY[Y_Legend[k]] = PlotValue
k = k + 1
NewPostX=[]
for k in range(len(Y_File)) :
for i in range(len(PostsX[k])):
NewPostX.append(PostsX[k][i])
NewPostX = list(set(NewPostX))
NewPostX.sort()process_column_X()という関数によって、ファイル名と、カラム番号、スケールファクタを指定してデータセットを作成しているが(詳細は後述)、系列ごとに取得したX軸データセットPostsX[k]から、新しく共通X軸データセットNewPostXを作成している(朱字部)。
次に、この横軸データセットを使って、元データの縦軸(Y)データセットを構築しなおす。つまり、
NewPostX:[x1 x1 x2 x3 x2 x3 x4]
Y : [y1 y2 y3 y4] ⇒ [y1 ## y2 y3 ## ## y4]
Y : [y1 y2 y3] ⇒ [## y1 ## ## y2 y3 ##]といった具合である。ここで ## と記した部分には、前後のデータを使って直線補間値をあてはめるというのが普通の考え方であろう。プログラムは、以下のようになった。
for k in range(len(Y_File)) :
iIns = 0
preFound = 0
for j in range(len(NewPostX)):
found = 0
imin = -1
for i in range(len(PostsX[k])):
if PostsX[k][i] == NewPostX[j]: #新X軸データに対応する元Y軸データが存在
found = 1
preFound = 0
break
if PostsX[k][i] < NewPostX[j] :
imin = i # 新X軸データに最も近い元データのカラム番号⇒imin
if found == 0: #新X軸データに対応する元Y軸データが存在しない場合には、補間データを作成
iL = imin
iH = iL + 1
try:
ratio = (NewPostX[j]-PostsX[k][iL])/(PostsX[k][iH]-PostsX[k][iL])
except:
ratio = 1
if iL < 0 :
insY = None
elif iH > len(PostsX[k])-1 :
insY = None
else:
insY = PostsY[Y_Legend[k]][iL+iIns-preFound] + (PostsY[Y_Legend[k]][iH+iIns]-PostsY[Y_Legend[k]][iL+iIns-preFound])*ratio
PostsY[Y_Legend[k]].insert(j,insY)
preFound = preFound + 1
iIns = iIns + 1
NewPostXのj番目の点において、相応するYデータが存在しない場合に、その前後(IL/ IH)のデータセットを使って補間値(insY)を計算して、 PostsY[Y_Legend[k]].insert(j,insY) としてYデータを追加している。但し前後のデータセットと記したが、この挿入操作を実行することで、元データの位置情報(IL/IH)と、再構築されたYデータの位置情報がずれてくるので、iIns や、preFoundといったカウンタを使って、その補正を行っている。
また、定義されたデータ範囲外のデータについてはそのまま水平もしくは勾配を延長するやり方も考えられたが、 i試行錯誤で nsY = None とすることで、プロットされなくなることがわかったのでこれを採用した。
あと、process_column_…にて、ポストデータファイルを読み込んで、データセットを作成する方法であるが、3つの類似型がある。基本は、process_column()であり、以下の内容になっている。
def process_column(plotFile,columnNumber,scaleFactor):
f = open(plotFile,"r")
text = f.readlines()
f.close()
postV = []
for line in text:
split = line.split()
if split[0] != "#" :
try:
postV.append( float((split[columnNumber].replace('(','')).replace(')','')) * scaleFactor )
except:
pass
return postVplotFileを読み込んで,注釈行(行頭が#)でなかったら、columnNumber位置の数字に,scaleFactorを掛けてデータセット(postV)に収納している。ベクトルデータなどは、括弧記号が数値と隣り合って表記される場合があるので、これを取り去ることも併せやっている。
process_column_vector(…)は、columnNumberで始まる3つの数字がベクトルデータであるという前提の元、ベクトルの絶対値を返すようにしたものである。
def process_column_vector(plotFile,columnNumber,scaleFactor):
f = open(plotFile,"r")
text = f.readlines()
f.close()
postV = []
for line in text:
split = line.split()
if split[0] != "#" :
try:
pX = float((split[columnNumber].replace('(','')).replace(')',''))
pY = float((split[columnNumber+1].replace('(','')).replace(')',''))
pZ = float((split[columnNumber+2].replace('(','')).replace(')',''))
pMag = math.sqrt( pX*pX + pY*pY + pZ*pZ )
postV.append( pMag * scaleFactor )
except:
pass
return postV
問題は、process_column_X(…)であろう。当初は、process_column(…)を使って、DEXCS標準チュートリアル問題では何ら問題が無かったのであるが、他の問題で遭遇した2番目の問題、つまり同一時間で複数の出力データが存在するケースでエラーになるのを回避する為の方策として、打算的な方法を考えたということである。
def process_column_X(plotFile,columnNumber,scaleFactor):
f = open(plotFile,"r")
text = f.readlines()
f.close()
preX=100000
epsX=1e-9
postV = []
for line in text:
split = line.split()
if split[0] != "#" :
try:
tempX = float((split[columnNumber].replace('(','')).replace(')','')) * scaleFactor
if preX == tempX :
postX = postX + epsX
else:
postX = float((split[columnNumber].replace('(','')).replace(')','')) * scaleFactor
preX = postX
postV.append( postX )
except:
pass
return postVやっていることは、読み取った値が以前の値(preX)に等しいかどうかを見て、等しかったら微少量(epsX = 1e-9)増やしてやろうというものである。この1e-9や、preX=100000という数字は、このままだとケースによっては不具合が生じる可能性もあるが、当面の処置ということにしておく。