DEXCSアドバンス版を作成した当初においては、CalculiXの並列計算までは考慮していなかったというのが実態です。同梱したAllrun-parallelにおいても、OpenFOAMの並列計算を考慮した内容でしかありません。
その後、Allrunスクリプト中に、CalculiX(実体はccx_preCICE) を起動する際に、
export OMP_NUM_THREADS=1
export CCX_NPROC_EQUATION_SOLVER=1という環境変数がある事に気付き、どうやらこの数字で並列度を変えられそうだとなりました。しかしながら、この数字を大きくすると、確かに速くはなるんですが、その効果は僅かなものでしかなかったというのが実状でした。
最近、比較的規模が大きく、なおかつCalculiXの計算時間が、OpenFOAMの計算時間より長くなってしまうような事例に遭遇する事となり、改めてなんとかならないものかと調べ直しました。そこで、よくよく計算ログ(Solve.log)を見直すと・・・
iteration 1
Using up to 4 cpu(s) for the stress calculation.
Using up to 4 cpu(s) for the symmetric stiffness/mass contributions.
Factoring the system of equations using the symmetric spooles solver
Using 1 cpu for spooles.
Using up to 4 cpu(s) for the stress calculation.
スレッド数を4にして計算しているので、確かに 4 cpu(s) というログになっているのですが、もっとよく見ると、spooles solver の部分では、1 cpu にしかなっていないという点に、今更ながら気付いたという事です。つまり、一番肝心な逆行列を計算するところで、マルチスレッド計算出来ていなかったという事です。
CalculiX(ccx本体)については、マルチスレッド計算用に、spoolesをマルチスレッド対応すれば良い・・・的な情報はたくさん存在するので、色々調べたのですがピンと来るものがありません。よくよく考えたら、ccx本体は関係なくて、ccx_preCICEをマルチスレッド対応させる必要があるんだということでした。そこで、調べ直すと、ようやくズバリの記事が見つかりました!
https://precice.discourse.group/t/calculix-parallelization/167
これはpreCICEのディスカッションボードの記事で、しかも時期的には2020年3月ということで、DEXCSアドバンス版に仕掛かっていた当時には既にわかっていた情報でした。これが当時のインストール情報ページには反映されていなかったという事です。ちなみに、このインストール情報ページも現在では、当時のものとは全く別物になってしまっています。これがpreCICEワールド!
何はともあれ、当時の calculix-adapter(ccx_preCICE)のビルド方法をベースに考えると、以下の2点につき、ビルド追加・変更すればよいということです。
SPOOLES
$ cd $HOME/CalculiX
$ cd SPOOLES.2.2/MT
$ make
これにて、MT/src/spoolesMT.a が生成される。
calculix-adapter
$HOME/preCICE/calculix-adapter-2.15_preCICE2.x/Makefileを、以下変更(朱字部分を追記)して
LIBS = \
\$(SPOOLES)/MT/src/spoolesMT.a \
\$(SPOOLES)/spooles.a \
\$(PKGCONF_LIBS) \
-lstdc++ \
-L$(YAML)/build -lyaml-cpp \
CFLAGS = -Wall -O3 -fopenmp $(INCLUDES) -DARCH="Linux" -DSPOOLES -DARPACK -DMATRIXSTORAGE -DUSE_MTコンパイルし、バイナリをコピーし直せば良いということです。
$ cd $HOME/preCICE/calculix-adapter-2.15_preCICE2.x
$ make clean
$ make
$ sudo cp bin/ccx_preCICE /usr/bin
つまり、当初のビルド方法では、spoolesMT(マルチスレッド)が組み込まれていなかったということです。
計算速度について
計算対象と計算内容について、現時点では公開できませんが、メッシュ規模と計算時間について比較した数値は公表しても問題無さそうなので以下に示しておきます。
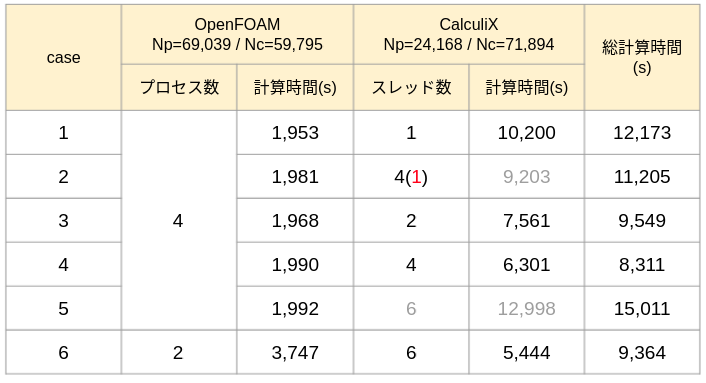
計算規模は表中に記したNp(節点数)Nc(要素数)の通りで、計算の時間送りステップ数は850、陰解法による繰り返し計算があって総ステップ数としては3730回の計算をしている。また、計算機のスペックは、Core i9-11900K @ 3.50GHz(Cores: 8)でメモリーは十分に余裕のある状態での結果です。
case2が、従来の方法によるもので、CalculiXのスレッド数を4に指定したものの、ccx_preCICEがMT対応していなかった為、case1 に比べてほんのわずか(10%以下)しかスピードアップしていなかった。case3以降が、MT対応のccx_preCICEで計算をやり直したもので、case5を除いて、スレッド数を増やすことによるスピードアップが得られた(とはいうもの、最大で2倍弱程度だが・・・)。
case5において、悪化しているのは、計算機の総コア数が8であり、OpenFOAMの占有分4を除いた4コアに対して6スレッドの処理には無理があるということのようです。
念の為、別のメニーコアの計算機(Xeon Gold 6130 @ 2.10GHz,16Core×2)にてやり直してみました。

但し、こちらはベースクロックが遅いので、計算の総ステップ数は1601回と少なくして実施したもの。総コア数に余裕があれば、先のような極端な速度低下はなく、基本的にコア数に応じて速度アップするが、6以上でほとんど頭打ち状態になる(2倍弱のスピードアップにしかならない)ことも確認できました。
但し、メッシュ数が変わった場合や、今回はCalculiXのメッシュがテトラの(2次要素でメッシュ作成が困難であった為)1次要素で作成してあるが通常は2次要素で計算したいところであり、このあたりの状況が変わった時の並列速度がどうなるかは、今後改めて調査する予定です。