国際化対応は(参考サイト)の記事を頼りに、おおまかには以下の手順
- ソースコードの修正
- 翻訳対象のテキスト抽出(.pot)
- テキストの翻訳(.po)
- 翻訳したファイルからリソースファイル(.mo)を作成
- システムからリソースを使用
で実施しましたが、(参考サイト)にも記してあるように、
gettextに関して説明しているページや書籍をみると、英語のテキストを日本語や各国語に翻訳している例がほとんどです。でも、そもそも日本人が作るプログラム・システムの大半では日本語のテキストはすでに存在するので、ここではすでにある日本語のメッセージをベースに英語やほかの言語に翻訳するという手順でやりたいと思います。
ということで、ここでも同じ方法でやったんですが、普通にやっていたら、ずいぶん面倒な作業になっていたかもしれません。
ソースコードの修正
DEXCSランチャーのソースコード(dexcs.py)は、wxGladeでコードを自動生成している部分と、自作の特定コード部分(ボタンやチェックボックスなどのコンポーネントに割りつけた関数などの内容部分)が混在しているのですが、前者については、コード出力する際に、Enable gettext support にチェックマークを入れれば、自動でやってくれます。
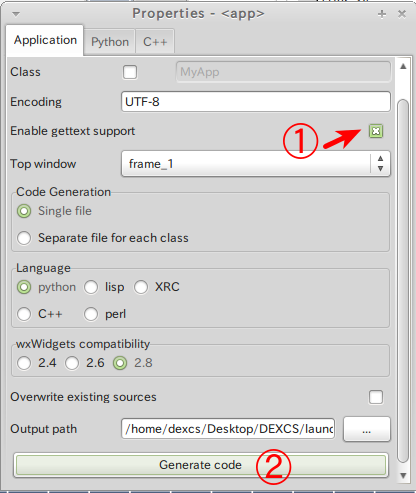
結果は、以下の朱字部分のように、メッセージ文字列が_()でくくられた形なります。
self.menu101 = wx.MenuItem(self.menu1, wx.NewId(), _(u”解析フォルダ新規作成”), “”, wx.ITEM_NORMAL)
self.menu1.AppendItem(self.menu101)
self.menu102 = wx.MenuItem(self.menu1, wx.NewId(), _(u”解析フォルダを開く”), “”, wx.ITEM_NORMAL)
self.menu1.AppendItem(self.menu102)
self.menu103 = wx.MenuItem(self.menu1, wx.NewId(), _(u”終了”), “”, wx.ITEM_NORMAL)
自作部分は、手修正でやりましたが、数時間の作業だったでしょうか。一回こっきりの作業なので、まぁ仕方なった。
但し、このままでほっといたら、動いてくれない。動かそうとすると、、、
Traceback (most recent call last):
File “./dexcs.py”, line 1605, in <module>
frame_1 = MyFrame(None, -1, “”)
File “./dexcs.py”, line 62, in __init__
self.menu101 = wx.MenuItem(self.menu1, wx.NewId(), _(u”解析フォルダ新規作成”), “”, wx.ITEM_NORMAL)
NameError: global name ‘_’ is not defined
つまり、せっかく文字列を _()で囲ってくれたけど、_が定義されてないってこと。で、これに対処するには、自動作成されたソースコードの冒頭あたりで、
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# generated by wxGlade 0.6.3 on Tue Aug 10 17:19:43 2010
# some bugFix by E.Mogura, May 21 2012import wx
import os
import re
import shutil
import fnmatch
import snappyDictExporter
import bcFilesConverter
import sys
import glob
from subprocess import *
import MyDialog1import gettext
gettext.install(“dexcs”,”/usr/share/locale”) # replace with the appropriate catalog nameclass MyFrame(wx.Frame):
def __init__(self, *args, **kwds):
朱字の2行(3行目は2行目の折り返しです)を追加しておく必要がある。
この意味は、getttextというモジュールをインポートすることで、先にエラーとされていた_()を解釈できるようになって、/usr/share/locale の下に、
locale
├── aa
│ └── LC_MESSAGES││(省略)
├── en_US
│ ├── LC_MESSAGES
│ │ └── mate-calc.mo│(省略)
├── ja
│ └── LC_MESSAGES
│ ├── apt.mo
│ ├── atril.mo
│ ├── banshee.mo
各言語用の翻訳辞書(.mo)がLC_MESSAGESの中に入っていて、dexcs.mo という辞書があったらそれを使って、_()部分を翻訳して出力する。。。ということになるらしい。
翻訳対象のテキスト抽出
基本は、gettext で対象となるソースコード(この場合は dexcs.py ) から、_()部分を抽出するんですが、ここでpygettext でなく、xgettextを使うところがミソでした。
$ xgettext -k”_” –from-code=UTF-8 dexcs.py
(オプションは無くても同じ結果でした)
出力ファイルを指定しなければ、message.po というファイルが出力される。
# SOME DESCRIPTIVE TITLE.
# Copyright (C) YEAR THE PACKAGE’S COPYRIGHT HOLDER
# This file is distributed under the same license as the PACKAGE package.
# FIRST AUTHOR <EMAIL@ADDRESS>, YEAR.
#
#, fuzzy
msgid “”
msgstr “”
“Project-Id-Version: PACKAGE VERSION\n”
“Report-Msgid-Bugs-To: \n”
“POT-Creation-Date: 2013-08-08 05:42+0900\n”
“PO-Revision-Date: YEAR-MO-DA HO:MI+ZONE\n”
“Last-Translator: FULL NAME <EMAIL@ADDRESS>\n”
“Language-Team: LANGUAGE <LL@li.org>\n”
“Language: \n”
“MIME-Version: 1.0\n”
“Content-Type: text/plain; charset=UTF-8\n”
“Content-Transfer-Encoding: 8bit\n”#: dexcs.py:64
msgid “解析フォルダ新規作成”
msgstr “”#: dexcs.py:66
msgid “解析フォルダを開く”
msgstr “”(以下省略)
テキストの翻訳
すでにお判りと思うが、 msgstr “” の部分に、青字のメッセージに対応する訳語を放り込んでおけばよいということです。このあたりは、訳語対応表を別に作っておいて、自動的に埋め込むなどしたいところですが、今回はすべて手作業です。
DEXCSランチャーに関しては、約180箇所あり、dexc.poをそのままGoogle翻訳させて、その結果をコピー&ペースト。細部を手直しといった作業で、これも数時間の作業量でした。
翻訳したファイルからリソースファイル(.mo)を作成
$ msgfmt -o dexcs.mo dexcs.po
dexcs.poはテキストファイルでしたが、リソースファイル(dexcs.mo)はバイナリです。単にバイナリ変換しているだけかというとそうでもなく、テキストファイルの修正作業中に誤って作業した場合や、訳語の対応で行頭や行末に改行マークがあった場合など、整合性をチェックしてくれるので助かります。
作成したリソースファイルを、所定の場所に収納します。
$ sudo cp dexcs.mo /usr/share/locale/en_US/LC_MESSAGES/
動作確認
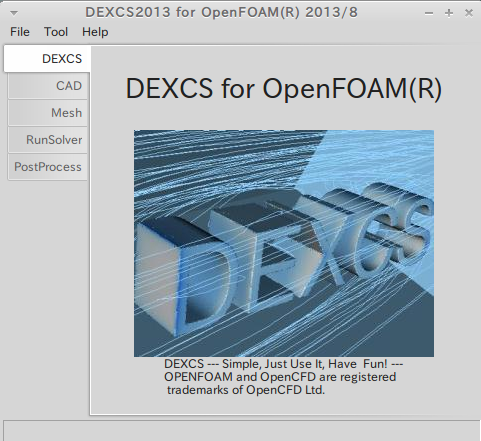
$ LANG=en_US.UTF-8
$ ./dexcs.py
$ LANG=ja_JP.UTF-8
$ ./dexcs.py
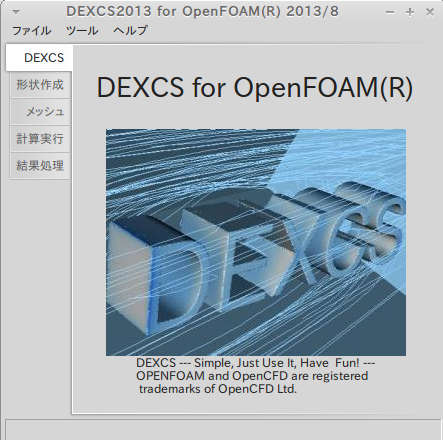
ということで、めでたし、めでたしでした。
今後の課題
とりあえず、ここまで出来ておれば「国際化対応版」という看板は上げられそうです。ただ訳語はいい加減で、もともとそこはもっと専門の人にやってもらえるような仕組みさえ構築しておけば良いと思ってやっているのですが、それ以外の課題もたくさんあります。
- 訳文の問題
- 訳文がいい加減のままである点以外にも、複数行に分けて表示している箇所があり、日本語と外国語の構文上の違いに起因して、翻訳がおかしくなる箇所がいくつか存在する。これには、メッセージは基本的に分割しないよう一文(改行マークは含んでいてもよい)で出力させるように、ソースコードそのものの見直しが必要になる。
- 切り替え方法の問題
- 本当は、メニューのどこかを開いて、言語選択できるようにすると良いのですがね。メニューを作ること自体はどうってことないのですが、その後でどういう処置をさせたら良いのかがわかりません。
- とりあえず、上で見たように、LANGを変更してコマンドラインから起動してもらう。
- もしくはDEXCSを仮想マシンなりにインストールする際、英語(en_US)を選択すれば、多分英語版が立ち上がると思いますが、動作は未確認です。
- DEXCSランチャー以外のコンポーネントの問題
- 英語版インストールが未確認なのは、確認できたところでその他のコンポーネント(TreeFoam や blender など)の対応問題が山積しているからです。
その他にもあるかもしれません。これらをどこまでやることになるのかは未定です。
翻訳対象のテキスト抽出(苦心譚)
普通にネット上で検索すると、pygettextでテキストを抽出しなさい、という情報がほとんどです。これでも出来ないことはないんですが・・・
$ pygettext dexcs.py
とコマンド入力すると、messege.pot というファイルが以下のように出力される
# SOME DESCRIPTIVE TITLE.
# Copyright (C) YEAR ORGANIZATION
# FIRST AUTHOR <EMAIL@ADDRESS>, YEAR.
#
msgid “”
msgstr “”
“Project-Id-Version: PACKAGE VERSION\n”
“POT-Creation-Date: 2013-08-07 17:13+JST\n”
“PO-Revision-Date: YEAR-MO-DA HO:MI+ZONE\n”
“Last-Translator: FULL NAME <EMAIL@ADDRESS>\n”
“Language-Team: LANGUAGE <LL@li.org>\n”
“MIME-Version: 1.0\n”
“Content-Type: text/plain; charset=CHARSET\n”
“Content-Transfer-Encoding: ENCODING\n”
“Generated-By: pygettext.py 1.5\n”#: dexcs.py:62
msgid “\350\247\243\346\236\220\343\203\225\343\202\251\343\203\253\343\203\200\346\226\260\350\246\217\344\275\234\346\210\220”
msgstr “”#: dexcs.py:64
msgid “\350\247\243\346\236\220\343\203\225\343\202\251\343\203\253\343\203\200\343\202\222\351\226\213\343\201\217”
msgstr “”(以下省略)
というように、日本語部分が文字コード(?)らしきもので出力されてしまいます。一応その前にソースコードの該当行がコメント出力されているので、ソースコードを横睨みしながら訳語を埋めていくことは出来て、このファイルからxgettextから作成したものと同等のリソースファイルが作れることも部分的ながら確認しましたが、ずいぶん面倒な作業になってしまいます。
そこで、文字コードを日本語に戻すツールがないものかとあれこれ調べたり、pygettext のオプションも調べたりしているうちに、ようやくxgettextにたどりついたという次第です。