計算性能は世界一には程遠いですが、新たにお金をかけることをしないで、既存の資源(家庭用のパソコン)だけを使って、どこまでスパコン(というほどではなく、PCクラスターが当面のターゲットですが)に近づけるのか・・・DEXCS-FLUSHの試用記です。
はじめに
今や普通のパソコン(32bitマシン)でも、一昔前のスパコンと同じ性能で、いわゆるCAEをやるのに充分な性能があるんですが、計算屋がなんでスパコンやPCクラスタを欲しがるかというと、大きく3つの要求があって、
- 高速な計算をしたい
- 大規模な計算をしたい
- 大量の計算を同時にやりたい
スパコンという言葉の一般的な印象からは、1.をイメージされる人が多いと思いますが、これを実現するには高速なネットワーク環境が必要になって、これはまだ普通の家庭では入手が困難です。もっとも最近のパソコンは一つのCPUの中に複数のコアを持つのが当たり前になってきたので、同一CPU内のコア間通信速度という意味で、ある程度期待できる面もありますが。ただここでは、まず2.の「大規模計算」というニーズに、FLUSHがどこまで応えられるかという面についてレポートします。付随して、1.の高速化についても、データを紹介しますが、こちらは今回の試験環境では望み薄でした。
我が家のパソコン
まずは今回使用したマシンの紹介です。我が家のパソコンは他にもありますが常用のものは対象にしていません。あくまで実践を想定して、自分が計算をやりたくなった時に、すぐに供用できるマシンを対象として選定しました。
1.Core2 Quad Q8400 / 4GB
約1年ほど前に購入した、自分のメインマシン。OSはWindows-XP。32bit版なので、メモリは3GB強しか使えていない。
2.Core2 Duo T8100 / 4GB
約2年前に購入した外出時用の携帯PCです。普段は何もさせていないので、計算サーバーとしては格好のマシンになります。
3.Mobile Athlon 3000+ / 2GB
10年くらい前に購入したマシンですが、約3年前、格安のマザーボードとCPUに交換して、時々色んな実験用に使っていました。しかし訳のわからないことをやりすぎたせいか、今やハードディスクからの立ち上げが困難な状態になっているマシン。ただCPUもメモリーもそこそこなので、計算サーバーには充分使えそう。
4.Pentium4 2.8G / 1.5GB
1年くらい前まで、自宅サーバーをやっていたマシン。購入したのは約6年前。現在は、最新のubuntuOS(9.10)上に最新のOpenFOAM-1.6.xを搭載するなど、実験用マシンとして使用。時々ムービープレーヤとしても使用。
ネットワーク
FLUSHの仕様というか推奨は独立した(切り離した)環境でしたが、ホームルーターのIPがデフォルトゲートウェイと同じだったことを幸いに、ホームルーターのDHCP機能を殺して、計算サーバー以外の既存マシンにFLUSHで使用しない固定IPを割り振ることで、通常のインターネットを使える環境の中でもFLUSHを使えるようになりました。
スイッチングHUBは、corega 5ポート Giga スイッチングハブ で、メーカーサイト(http://www.corega.co.jp/prod/sw05gtplx/)によれば、「Jumbo Frame」(12KByte)対応により、ギガビットイーサネットの高速性能を最大限発揮できます・・・とのこと。よくわからないけど、各パソコンのネットワークカードが、100BASEなので、ここで律速される心配はなさそう。。。ということです。
機器の構成
これらの機器に、FLUSH計算サーバー、FLUSH管理ホスト、DECXSランチャーを搭載した仮想マシン(本当はDEXCSランチャーを搭載した仮想マシンがFLUSH管理ホストの役目も担ってくれるとユーザーには判りやすいと思うのですが・・・)を、それぞれどう割り当てたらいいのか?正解がありそうで、なさそうな???色々試行錯誤しながらやってみることにしました。
構成Ⅰ

まずは日頃使い慣れたメインマシンに、FLUSH管理ホストと、DECXSランチャーを搭載した仮想マシンを搭載して、その他のマシンをFLUSH計算サーバーにするという構成で、ま、一番ふつうのやり方ですね。計算したい規模に合わせて、FLUSH計算サーバーの(電源をオンにする)台数を増やしていけば良いのですから。
また、こういう使い方をするとなると、なお更、DEXCSランチャーを搭載した仮想マシンとFLUSH管理ホストを一体化して欲しくなります。
ただ、結局、この使い方では「並列計算では一番プアなマシンで律速されてしまう」という落とし穴がありました。
もちろん、並列計算する際の領域分割で、各マシンへの負荷配分を、マシン能力に応じて相応の配分ができればこの問題は解消できるかもしれませんが、現時点ではそのやり方もわからないので、均一な負荷分散しか出来ないという前提です。ここでは、
- マシン1. ⇒ FLUSH管理ホスト&DEXCS-OpenFOAM
- マシン2. ⇒ 計算サーバー1. CPU数=2、メモリ=2GBx2
- マシン3. ⇒ 計算サーバー2. CPU数=1、メモリ=2GB
- マシン4. ⇒ 計算サーバー3. CPU数=1、メモリ=1.5GB
ということで、全4CPUを使った並列計算が可能なのですが、3.のマシンのメモリ搭載量が1.5GBなので、トータルでは
4 x 1.5 = 6GB
しか使えないということです。特にFLUSH計算サーバーの設定としてスワップを持たない仕様になっていたので、3.のマシンでメモリ使用量が1.5GBに到達した瞬間に、計算が終了してしまうという場面に、何度も遭遇しました。
6GB必要な計算ということであれば、1.と2.のマシンを3並列で計算できれば充分です。3.のマシンはCPU速度も遅いので、4並列で計算すると、むしろ遅くなってしまいます。数字は微妙な違いでしかありませんが、3.のマシンはあってもなくてもほとんど意味がないということになってしまっています。それならば、と考えたのが構成Ⅱです。
構成Ⅱ

- マシン1. ⇒ 計算サーバー1. CPU数=4、メモリ=1GBx4
- マシン2. ⇒ 計算サーバー2. CPU数=2、メモリ=2GBx2
- マシン3. ⇒ 計算サーバー3. CPU数=1、メモリ=2GB
- マシン4. ⇒ FLUSH管理ホスト&DEXCS-OpenFOAM
計算サーバーとしては意味をなさなかったマシン4.を、FLUSH管理ホストと、DEXCSランチャーを搭載した仮想マシンに割り当てました。ただ、本当にやりたかった事は、
- マシン1. ⇒ 計算サーバー1′. CPU数=2、メモリ=2GBx2
とすることで、計算サーバー1.から1′.への変更は、gridEngineの設定で可能と聞いたのですが、これができれば、総CPU数5。搭載メモリは各2GBとなるので、全10GB使用可能となるはず。ただFLUSHの現ヴァージョンでは、メモリ1GB搭載CPUが4つという使い方になってしまう。それでも総CPU数7×最小メモリ(1GB)=7GBとなって、構成Ⅰに比べれば大容量環境が構築できるはずという目論見でした。
この構成で実施したいくつかの計算例を表に示す。並列計算実施例としては、計算サーバー1.もしくは2.の内部での並列計算例があるのみで、複数の計算サーバーにまたがる並列計算は、最後の実施例だけです。
計算規模が大きくなるにつれ計算時間が長くなっていくのは当然の事として、問題は並列計算そのものでなく、計算の前処理、後処理にも相応の時間がかかり、使用メモリも多く必要になってくるということ。特に、snappyHexMesh作成後のreconstruction。この後処理時間は記録していなかったので正確な数字ではありませんが、せっかく並列処理によってわずかばかり高速化できた分はあったのですが、あっさりこの後処理で使い切ってしまっていました。総メッシュ数が100万を超えるようになると、これをサクサク扱えるようにするには、6年も前に購入したマシン4.では無理があったということです。
ただ、OpenFOAMでメモリが一番必要とされるのはsnappyHexMeshを実行する段階でなので、この並列計算を実施するまでの段階であれば、この構成で実現可能なので、これはこれで一つの選択肢として使えそう。ただ、snappyHexMeshの並列計算を実施した後のreconstructionは、構成Ⅰまたはつぎの構成Ⅲで実施するしかないようです。
構成Ⅲ
こうして最終的に到達した現実解が以下の構成です。
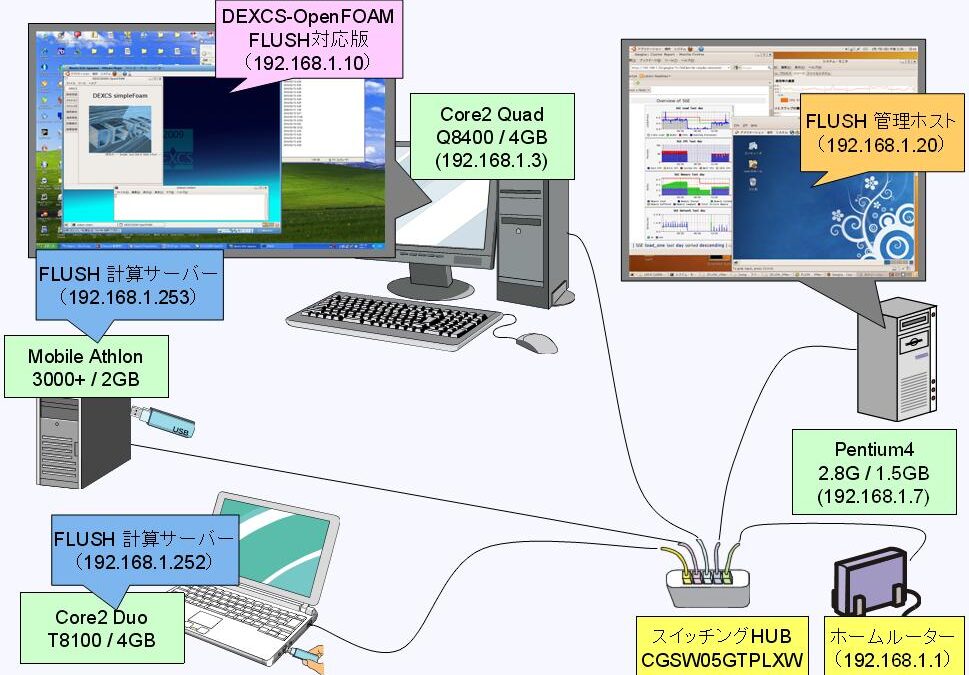
- マシン1. ⇒ DEXCS-OpenFOAM メモリ=1~2.7GB on Windows-XP(32bit)
- マシン2. ⇒ 計算サーバー1. CPU数=2、メモリ=2GBx2
- マシン3. ⇒ 計算サーバー2. CPU数=1、メモリ=2GB
- マシン4. ⇒ FLUSH管理ホスト
構成Ⅰとの違いは、FLUSH管理ホストをマシン1.から、存在理由のなかったマシン4.へ移動したという点。マシン1.のDEXCS-OpenFOAMで、メモリを最大限使用できるようになって、並列計算の前処理・後処理もいくぶん楽になります。というか、100万メッシュ以上の大きな計算をする場合には、DEXCSランチャーにも高性能のマシンでメモリーをたくさん用意してやらないと快適な環境にはなりません。
計算結果のサマリー
{kind=link}

計算方法と結果に関する補足説明
- 計算に使用したモデルはDEXCS-OpenFOAMの標準テンプレートモデルで、メッシュサイズを各種変更した。
- メッシュサイズの変更には、snappyHexMeshDictのSurface細分化パラメタ(Smin,Smax)を変更するのと、基礎メッシュのブロック分割数(Nx,Ny,Nz)を変更するのを併用した。それぞれ、snappyHexMeshDict、bolockMeshDictを直接編集で変更した。
- 上段の4つ(TestNo.[0-1] ~ [0-4] )は、単体計算の結果で、DEXCS2009-OpenFOAMの公開版と同等の仮想マシンにて実施したもので、第2回オープンCAEワークショップで発表した資料(http://www.opencae.jp/data/OpenSourceCAEWorkshop/200911/slides/OpenSourceCAEWorkshop200911Nomura.pdf) の15ページ目に記載したベンチマークデータの元資料となったデータ。
- 計算時間(meshTime,exeTime,clockTime)は、計算出力ログから転記したもの。
- 計算サーバーでの計算で、並列計算でないもの(使用コア数=1)は、mpirunコマンドを手打ちして実行したもの。
sudo rsh -l root Fserv /opt/OpenFOAM/ThirdParty/openmpi-1.2.6/platforms/linuxGccDPOpt/bin/mpirun -mca pls_rsh_agent rsh -np 1 -machinefile /root/machines /opt/OpenFOAM/OpenFOAM-1.5.x/applications/bin/linuxGccDPOpt/snappyHexMesh -case /root/DATA/mesh2 &
- ブロック分割数が大であるのにメッシュサイズの上昇があまり見られないデータが存在するのは、snappyHexMeshDictの中で、maxGlobalCells(snappyHexMeshDict中、70行目)のサイズ調整が不十分だったことに起因(細分化を途中段階で停止している為)。
- simpleFoamの計算では、収束が不十分なままイタレーションを停止した場合の結果も掲載してある。
- simpleFoamの計算で、100万メッシュを超える場合、乱流モデルがk-epsillonでは発散してしまうので、k-omegaSSTを用いた。
計算結果の分析例(わかったこと)
- Windows上の仮想マシンで計算するのと、今回の計算サーバー(Linuxネイティブ)で計算することによる違いは僅か。TestNo.[0-4] と [2-15] を比較、または[0-3] と [2-13]を比較。
- 同一CPU内の並列計算による速度向上は2並列計算で、10~30%アップにとどまった。[2-4]と[2-3]の比較、[2-13]と[2-12]の比較、[2-15]と[2-14]の比較
- 2並列計算を4並列計算してもほとんど変化はない。[2-2]と[2-1]の比較、[2-11]と[2-10]の比較
- 性能の劣るマシンを混在させなくても可能な計算に、このマシンを加えて並列度を上げた計算を実施しても、速度は却って低下する。[1-4]と[1-5]の比較、[3-1]と[3-2]の比較
- FLUSH管理ホストを搭載するマシンの性能に応じて全体速度も変化するが、寄与度は少ない([1-5]と[2-22]の比較)
最後に、今回のテストで最大規模だった計算結果の一例を添付しておきます(TestNo.[2-22])

総セル数:3,169,802 / 総節点数:4,062,360
- 計算は未収束(イタレーション回数100で強制終了)です。
- 可視化はvtk変換(FoamToVTK)したものを、paraViewで表示。
- vtk変換するのに、仮想マシンへの割り当てメモリが2.7GBでは不足。3.0GBにしてようやくOKでした。
- paraFoamによる可視化は論外。
まとめ
- 既存の32bitマシン4台(総メモリ容量11.5GB)を使って、最大で、7CPU x 1GB 、300万要素(400万節点)の並列計算が可能になった。
- 総じて並列計算による高速化効果は少なく、あっても後処理のオーバーヘッドにより相殺されてしまった。メモリ不足を補う目的での並列化には効果があった。
- 供用マシンのメモリー容量差がなければ、より大容量の計算も原理的には可能と推察された。
- 但し、並列計算した後のポスト処理に課題があり、paraviewの並列化は必達要件になる他、reconstructionを実行するにもリッチな環境が必要になりそう。
気付いた点
- gangliaで稼動状況を見るには、FLUSH管理ホストの設定メモリがデフォルト(128MB)では不足。256MBでも駄目だった。512MBではOK。
- FLUSH管理ホストをマシン4.に設定(構成Ⅱまたは構成Ⅲ)だと、マシン1.のWindows環境からGangliaの稼動状況を参照可能だが、マシン1.にFLUSH管理ホストを搭載すると、マシン1.のWindows環境からは参照できない。管理ホストそのものからは参照可能。またWindows環境から管理ホストに対してpingは通るんだが、、、
- FLUSHで実行可能なOpenFOAMソルバーは標準ソルバーのみ。ソース変更などしてもコンパイルできない。
- DEXCSランチャー上でwmakeできても、FLUSH上では動かない。
要望
- 複数のDEXCSランチャー搭載マシンから計算実行できるようにならないか?IPが決めうち(192.168.1.10)になっており、他のIPが振ってあると、マウントをかけられない?都度パスワードを要求される。
- 上記要望の背景として、DEXCSランチャーはある程度ポータブルなので、Linuxネイティブマシンに搭載したDEXCSランチャーから起動したいなどを想定している。
- paraviewの分散処理は必須
- OpenFOAMの開発環境も動かせるようにしてもらいたい
- 計算サーバーではスワップを使えるようにしてほしい
- バッチ(qsub)でジョブを投入できるようにしてほしい